Hazelcast이란 무엇인가요?
Hazelcast는 분산 데이터 저장 기능을 제공하는 인메모리 데이터 그리드(IMDG)입니다. 이를 통해 응용 프로그램은 여러 노드 간에 데이터 및 계산을 분산하여 확장할 수 있습니다. Hazelcast의 주요 기능에는 분산 캐싱, 인메모리 데이터 저장, 확장성 및 내구성, 분산 컴퓨팅, API 및 통합이 포함되어 있습니다. Hazelcast를 활용하면 데이터 집약적이고 실시간 처리 환경에서 응용 프로그램이 높은 성능, 확장성 및 내구성을 달성할 수 있습니다.
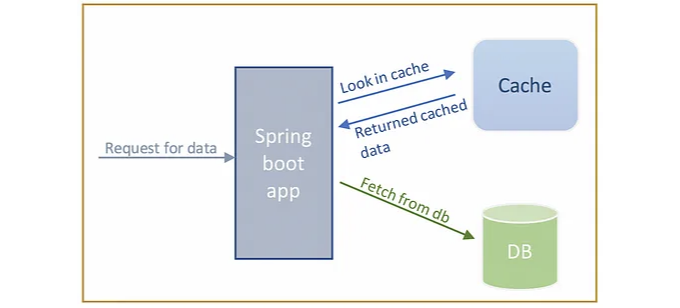
이 블로그 포스트에서는 Hazelcast를 Spring Boot 응용 프로그램의 캐시 관리자로 활성화하는 방법을 단계별로 설명하겠습니다.
1- 시작하기
Hazelcast를 캐시 관리 도구로 사용하려면 클래스패스에 추가하세요
<!--Hazelcast-->
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.4.0</version>
</dependency>
2- Hazelcast 구성
이 작업을 수행하는 세 가지 방법이 있습니다. 1- hazelcast.yaml 구성 추가 또는 2- hazelcast.xml 구성 추가 또는 3- 소스 코드에서 Hazelcast 구성과 함께 @Bean을 정의합니다.
이 문서에서는 애플리케이션에 더 많은 제어권을 제공하는 세 번째 방법을 탐구하겠습니다.
package com.swapy.hazelcast_app.config;
import com.hazelcast.config.*;
import com.swapy.hazelcast_app.Entity.Student;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableCaching
public class HazelcastConfig {
private static final String CLUSTER_NAME = "students-cluster";
private static final String MAP_NAME = "students";
private static final int MAX_SIZE = 200;
private static final int TTL_SECONDS = 3600;
private static final int FACTORY_ID = 1;
@Bean
public Config hazelcastConfig() {
Config config = new Config();
// Set the cluster name
config.setClusterName(CLUSTER_NAME);
// Configure network settings (multicast for simple setup)
NetworkConfig networkConfig = config.getNetworkConfig();
JoinConfig joinConfig = networkConfig.getJoin();
MulticastConfig multicastConfig = joinConfig.getMulticastConfig();
multicastConfig.setEnabled(true);
// Configure a map (cache) with eviction policy
MapConfig mapConfig = new MapConfig();
mapConfig.setName(MAP_NAME);
EvictionConfig evictionConfig = new EvictionConfig()
.setSize(MAX_SIZE)
.setMaxSizePolicy(MaxSizePolicy.FREE_HEAP_SIZE)
.setEvictionPolicy(EvictionPolicy.LRU);
mapConfig.setEvictionConfig(evictionConfig);
mapConfig.setTimeToLiveSeconds(TTL_SECONDS); // 1 hour TTL
config.addMapConfig(mapConfig);
// Hazelcast IdentifiedDataSerializable
config.getSerializationConfig().addDataSerializableFactory(
FACTORY_ID, classId -> (classId == 1) ? new Student() : null
);
return config;
}
}
Map Configuration: "students"라는 이름의 map이 특정 설정과 함께 구성되었습니다. LRU(Least Recently Used) 알고리즘에 기반한 뒤쳐진 정책 및 자유 힙 크기에 따라 최대 크기가 결정됩니다. 또한 map에는 한 시간 후에 항목이 자동으로 제거되도록 하는 TTL(Time-To-Live) 설정이 있어 메모리를 관리하고 데이터를 신선하게 유지합니다. 사용자 정의 직렬화: Hazelcast의 IdentifiedDataSerializable 인터페이스를 사용하여 Student 클래스에 대한 사용자 정의 직렬화를 정의합니다. 이 방법은 객체에 대한 명시적인 읽기 및 쓰기 메서드를 제공하여 Java의 기본 직렬화에 비해 성능이 향상되고 직렬화 오버헤드가 줄어듭니다.
네트워크 설정: 구성은 네트워크 탐색을 위해 멀티캐스트를 활성화하여 Hazelcast 노드가 간단한 로컬 네트워크 설정에서 서로 자동으로 인식할 수 있도록 합니다.
3. 사용자 지정 직렬화 추가:
package com.swapy.hazelcast_app.Entity;
import com.hazelcast.nio.ObjectDataInput;
import com.hazelcast.nio.ObjectDataOutput;
import com.hazelcast.nio.serialization.IdentifiedDataSerializable;
import jakarta.persistence.*;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.IOException;
@Entity
@AllArgsConstructor
@NoArgsConstructor
@Data
@Table(name = "student_table")
public class Student implements IdentifiedDataSerializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String firstName;
private String lastName;
private int age;
@Override
public int getFactoryId() {
return 1; // Ensure this matches with your factory configuration
}
@Override
public int getClassId() {
return 1; // Ensure this matches with your class configuration in the factory
}
@Override
public void writeData(ObjectDataOutput out) throws IOException {
out.writeInt(id != null ? id : -1); // Handle nulls appropriately if needed
out.writeString(lastName);
out.writeInt(age);
out.writeString(firstName);
}
@Override
public void readData(ObjectDataInput in) throws IOException {
id = in.readInt();
if (id == -1) { // Assuming -1 is used as a marker for null
id = null;
}
lastName = in.readString();
age = in.readInt();
firstName = in.readString();
}
}
팩토리 및 클래스 ID: getFactoryId 및 getClassId 메서드는 1을 반환하며, 이는 Hazelcast의 직렬화 팩토리에서의 구성과 일치해야 합니다. 이 ID들은 객체의 직렬화 스키마를 식별하기 위해 사용되며, 서로 다른 Hazelcast 인스턴스 간에 일관성을 유지합니다.
4- 데이터 생성 및 읽기
CRUD 작업을 수행하는 간단한 컨트롤러가 작성되었습니다.
package com.swapy.hazelcast_app.controller;
import com.swapy.hazelcast_app.Entity.Student;
import com.swapy.hazelcast_app.service.StudentService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.CacheConfig;
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.cache.annotation.CachePut;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/api/students")
@Slf4j
public class StudentController {
@Autowired
private StudentService studentService;
@GetMapping
public List<Student> getAllStudents() {
return studentService.getAllStudents();
}
@GetMapping("/{id}")
@Cacheable(value = "students", key="#id")
public Student getStudentById(@PathVariable Integer id) {
// Adding a delay to represent the scenario when data is not present in cache
// and get fetched from DB
try{
Thread.sleep(2000);
}catch ( InterruptedException e ){
System.out.println("Something went wrong");
}
return studentService.getStudentById(id);
}
@PostMapping
public Student createStudent(@RequestBody Student student) {
return studentService.createStudent(student);
}
@PutMapping("/{id}")
@CachePut(value = "students", key="#id")
public Student updateStudent( @RequestBody Student student,@PathVariable Integer id) {
return studentService.updateStudent(student , id);
}
@DeleteMapping("/{id}")
@Cacheable(value = "students", key="#id")
public Student deleteStudent(@PathVariable Integer id) {
return studentService.deleteStudent(id);
}
}
캐시 주석: 컨트롤러에서 스프링의 캐싱 주석인 @Cacheable, @CachePut 및 @CacheEvict를 사용하여 학생 엔티티에 대한 캐싱 동작을 관리합니다. 예를 들어, 메서드에 @Cacheable 주석이 있는 경우 ID별 학생 가져오기 결과가 캐시에 저장되어 데이터베이스 부하를 줄이고 반복 요청에 대한 응답 시간을 개선합니다.
5- 애플리케이션 시작
시작시 로그에서 내장 Hazelcast가 시작되고 멤버가 생성되어 클러스터에 추가된 것을 확인할 수 있어야 합니다.

6- 어플리케이션 테스트
포스트맨이나 curl을 사용하여 어플리케이션을 테스트할 수 있습니다. 처음 getStudentById API를 사용할 때는 상당한 지연이 발생하며, 이후의 작업은 매우 빠릅니다.
추가로 읽을거리:
더 많은 정보를 원하시면 Hazelcast의 공식 문서 페이지로 이동해주세요: https://docs.hazelcast.com/home/