![]()
당신은 LLM에게 완벽한 질문을 할 것이라고 가정하는 것보다 더 틀릴 수 없어요. 직접 실행하는 대신 사용자의 문제를 미련하게 잘 다듬을 수 있을까요? 그것이 쿼리 번역입니다.
우리는 회사가 지금까지 생산한 모든 문서를 쿼리할 수 있는 앱을 만들었어요. 이에는 PPT, 프로젝트 제안서, 진행 상황 업데이트, 결과물, 문서 등이 포함돼 있어요. 지난 시도들이 부족했을 때, RAGs 덕분에 이번에는 매우 유망했어요.
우리는 시연을 했고, 모두가 사용하기를 열망했어요. 초기 롤아웃은 소수의 선별된 직원 대상으로 이루어졌어요. 그러나 우리가 발견한 것은 우리에게는 그리 흥미로운 것이 아니었어요.
이 작업 방식을 바꾸는 중요한 역할을 할 것으로 예상되었어요. 그러나 대부분의 사용자들은 앱을 몇 번 시도한 뒤에는 사용하지 않았어요. 그들은 학교 어린이들을 위한 장난감 프로젝트인 것처럼 앱을 떠났어요.
로그는 만족스러운 결과를 보여줬어요. 그러나 우리는 앱을 사용한 진짜 사용자들과 대화를 나눠서 진짜 문제를 파악했어요. 우리가 배운 교훈으로 사용자 입력의 모호함을 극복하기 위한 쿼리 번역 기술에 대해 고민할 수 있었어요.
다음은 예시 상황이에요.
한 사용자가 저희의 고객 중 하나인 "XYZ"가 획득할 패션 관련 비즈니스에 관심이 있어요. 그의 입력은 "XYZ 파트너가 한 패션 관련 획득은 무엇인가요?" 였어요. 앱은 저희가 제공하는 PPT를 검색하여 한 차례에 다섯 회사의 목록을 제시했어요. 하지만, 이 목록은 사용자가 기대하는 것과는 너무 다르더라구요. XYZ 파트너사들은 (예를 들어) 7개의 패션 상점을 인수했지만, 우리가 얻은 목록엔 4개만 있었어요. 사용자는 테스터이기도 하기 때문에 몇 번의 인수가 있었는지 잘 알고 있어요.
사람들이 도구를 사용하는 것을 그만둔 이유가 당연하네요. 그러나 단계별 롤아웃 기술 덕분에 상실된 신뢰를 회복할 수 있게 되었어요.
우리는 이 문제를 해결하기 위해 앱에 일련의 변경을 가했어요. 한 가지 중요한 업데이트는 쿼리 번역이었죠.
이 게시물은 서로 다른 쿼리 번역 기술을 소개하는 취지이지만 깊은 내용을 다루지는 않아요. 예를 들어, 이러한 기술 중 일부는 피드백 기법과 사고의 연쇄와 같은 유도 기법과 결합할 수 있어서 더 나은 결과를 얻을 수 있어요. 그러나 이러한 기술들은 미래의 다른 게시물을 위한 것이에요.
한 가지씩 기술을 살펴보겠죠. 그런데 그 전에 기본적인 RAG 예시가 있어요.
기본 RAG 예시
모든 RAG 애플리케이션에는 적어도 하나의 데이터베이스가 필요하며, 종종 벡터 저장소와 언어 모델이 함께 사용됩니다. RAG의 기본 아이디어는 간단합니다. LLM이 사용자의 질문에 이전 지식을 활용하여 답변하기 전에, 데이터베이스를 검색하여 맥락 정보를 찾고 더 정확한 응답을 생성합니다.
다음 다이어그램은 가장 간단한 RAG 앱을 나타냅니다.
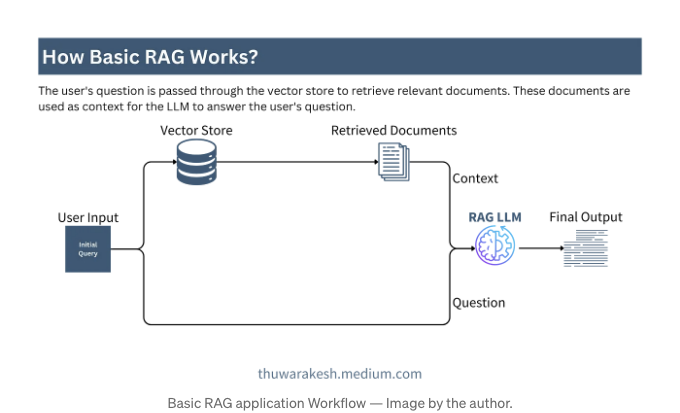
간단한 RAG 애플리케이션에서는 LLM 모델과의 단일 통신만 존재합니다. 이는 OpenAI GPT 모델, Cohere 또는 로컬에서 호스팅하는 모델일 수 있습니다.
다음 코드는 다이어그램의 단계를 구현합니다. 이를 기반이하여 글에서 다른 기술을 더 추가해 나갈 것입니다.
# 비밀을 안전하게 로드하기 위한 코드
from dotenv import load_dotenv
load_dotenv()
# 1. 내용 로드
# -----------------------------------------
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://docs.djangoproject.com/en/5.0/topics/performance/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
id="docs-content"
)
),
)
doc_content = loader.load()
# 2. 색인화
# -----------------------------------------
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=200
)
docs = text_splitter.split_documents(doc_content)
vector_store = Chroma.from_documents(documents=docs, embedding=OpenAIEmbeddings())
retriever = vector_store.as_retriever()
# 3. LLM
# -----------------------------------------
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0.5)
# 4. RAG Chain
# -----------------------------------------
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
prompt = """
아래 문맥에서 질문에 답해주세요:
{context}
질문: {question}
"""
prompt_template = ChatPromptTemplate.from_template(prompt)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt_template
| llm
| StrOutputParser()
)
# 5. 체인 실행
# -----------------------------------------
response = chain.invoke(
"사이트 속도를 향상시키는 방법은 무엇인가요?",
)
print(response)
위 코드에서는 Django 문서 페이지를 로드하고 Chroma 벡터 저장소에 저장하기 위해 웹 기반 로더를 사용했습니다. 문서 페이지 대신 다양한 웹 페이지, 로컬 텍스트 파일, PDF 등과도 실험해볼 수 있습니다.
우리는 정교한 검색 기술을 사용하지 않기 때문에 검색기를 바로 최종 RAG 체인으로 전달했습니다. 후속 기술에서는 검색기 그 자체 대신 다른 검색기 체인을 전달할 것입니다. 기사의 나머지는 검색 체인을 구성하는 방법에 대해 설명합니다.
Step-back 프롬프팅
Step-back 프롬프팅은 기본 RAG와 매우 유사합니다. 초기 질문을 사용자에게 요청하는 대신 보다 일반적인 질문으로 데이터베이스에서 문서를 검색합니다.
보다 넓은 질문은 구체적인 질문보다 맥락 정보를 더 포착합니다. 결과적으로 최종 LLM은 사용자에게 더 도움이 되는 정보를 제공할 수 있습니다.
초기 질의가 너무 구체적이고 자세하지만 전반적인 전망이 부족한 경우에는 종종 유용합니다.
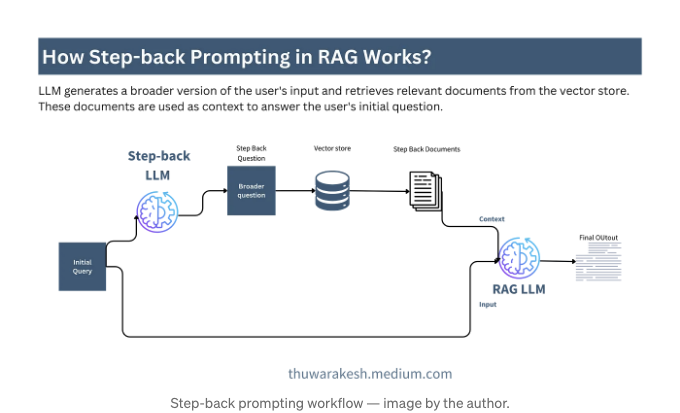
여기 단계별 프롬프팅 코드 구현이 있습니다. RAG 예제에서 재검색기 자체를 전달한 다른 구조를 사용한다는 점에 주의하세요.
# 4. RAG Chain
# -----------------------------------------
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 4.1 Step back prompting
step_back_prompt = """
당신은 전문 소프트웨어 엔지니어입니다.
주어진 질문을 더 일반적인 형태로 재구성하여 답변하기 쉽게 하는 것이 당신의 임무입니다.
# 예제 1
질문: Django 성능을 향상시키는 방법은 무엇인가요?
출력: 웹 앱 성능에 어떤 요소가 영향을 미치나요?
# 예제 2
질문: Django에서 브라우저 캐시를 최적화하는 방법은 무엇인가요?
출력: 서로 다른 캐싱 옵션은 무엇인가요?
질문: {question}
출력:
"""
step_back_prompt_template = ChatPromptTemplate.from_template(step_back_prompt)
retrieval_chain = step_back_prompt_template | llm | StrOutputParser() | retriever
# 4.2 RAG chain
prompt = """
아래 상황에서 질문에 대답하세요.
귀하의 응답은 종합적이어야 하며 다음 상황과 모순되지 않아야 합니다.
상황이 질문과 관련이 없으면 "잘 모르겠어요"라고 말하세요:
{context}
질문: {question}
"""
prompt_template = ChatPromptTemplate.from_template(prompt)
rag_chain = (
{"context": retrieval_chain, "question": RunnablePassthrough()}
| prompt_template
| llm
| StrOutputParser()
)
단계 후퇴 프롬프팅은 전반적인 맥락이 중요한 응용 프로그램에 유용합니다. LLM은 관련 질문에 일관된 답변을 제공할 것입니다.
HyDE (가상 문서 임베딩)
HyDE는 최근에 인기있는 문서 검색 기술입니다. 아이디어는 LLM의 사전 지식을 사용하여 문서를 생성하는 것입니다. 그런 다음 문서는 벡터 저장소에서 관련된 컨텍스트를 검색합니다.
HyDE의 좋은 사용 사례는 사용자가 문제를 설명할 때 종종 초보자 용어를 사용하지만, 벡터 저장소에 있는 정보가 매우 기술적인 경우입니다. 게다가 LLM의 설명은 관련 정보를 검색하기 위한 더 많은 키워드를 가지고 있습니다.
예를 들어, "Django 성능을 개선하는 10가지 방법"과 같은 쿼리는 비용 요소, 캐싱, 압축 등을 포함한 종합적인 답변을 제공할 것입니다.
위 다이어그램에 대한 코드 구현은 다음과 같습니다. 이번에는 HyDE를 사용하여 검색 체인을 재구성하는 스니펫만 제공했습니다.
# 4.1 HyDE 프롬프팅
hyde_prompt = """
You're an AI language assistant.
Your task is to generate a more broader version of the question below.
By doing so, you're helping the user with more information.
Don't explain the question. Only provide a more broader version of it.
Question: {question}
Output:
"""
hyde_prompt_template = ChatPromptTemplate.from_template(hyde_prompt)
retrieval_chain = hyde_prompt_template | llm | StrOutputParser() | retriever
다중 쿼리
다중 쿼리는 벡터 저장소에서 거리 기반 검색의 문제를 극복하는 데 도움이 되는 기술입니다. 대부분의 벡터 저장소는 벡터화된 문서를 검색하기 위해 코사인 유사도를 사용합니다. 이 방법은 문서들이 일정한 유사성을 가질 때 잘 작동합니다. 그러나 거리 기반 유사성이 없는 경우 검색 프로세스가 문제가 될 수 있습니다.
다중 쿼리 접근 방식에서는 LLM에게 동일한 쿼리의 여러 버전을 생성하도록 요청합니다. 예를 들어 "Django 앱 속도를 높이는 방법"과 같은 쿼리는 "Django 기반 웹 앱 성능을 향상시키는 방법"으로 다른 버전으로 번역될 수 있습니다. 이러한 쿼리들을 함께 사용하여 벡터 저장소에서 더 많은 관련 문서를 검색할 수 있습니다.
중간 단계로, 이러한 문서들을 최종 RAG-LLM에 전달하기 전에 고유한 문서 목록을 만들어야 합니다. 이는 한 쿼리가 동일한 문서를 여러 번 검색할 가능성이 높기 때문입니다. 중복된 상태에서 모두 전달하면 LLM의 토큰 한도에 도달하여 오히려 문제가 될 수 있습니다.
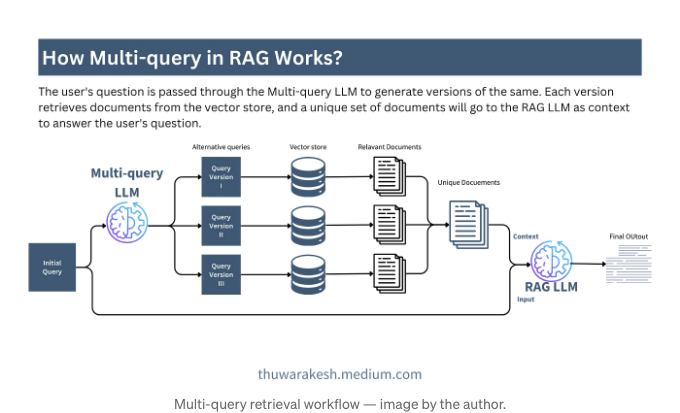
코드 구현에는 문서를 중복 처리하는 추가 기능이 있습니다. 나머지는 다른 방법들과 동일합니다.
from langchain.load import loads, dumps
def get_unique_documents(documents: list[list]) -> list:
# 리스트의 리스트를 평평하게 펴고 각 문서를 문자열로 변환합니다.
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
# 고유한 문서를 가져옵니다.
unique_docs = list(set(flattened_docs))
# 반환
return [loads(doc) for doc in unique_docs]
# 4.1 Multi-query prompting
multi_query_prompt = """
당신은 AI 언어 모델 어시스턴트입니다.
사용자의 질문에서 문서를 가져 오기 위해 사용자의 질문의 다섯 가지 버전을 만드는 것이 당신의 작업입니다.
사용자의 질문에 대해 여러 관점을 제공함으로써 사용자가 거리 기반 유사성 검색의 일부 제한을 극복하는 데 도움을주는 것이 목표입니다.
새 줄마다 대체 질문을 제공하십시오.
질문: {question}
결과:
"""
multi_query_prompt_template = ChatPromptTemplate.from_template(multi_query_prompt)
retrieval_chain = (
multi_query_prompt_template
| llm
| StrOutputParser()
| (lambda x: x.split("\n"))
| retriever.map()
| get_unique_documents
)
RAG-Fusion
RAG 퓨전은 문서 검색에서 멀티 쿼리와 유사합니다. 다시 한 번 LLM에게 초기 쿼리의 여러 버전을 생성하도록 요청합니다. 그런 다음 이러한 버전에 대해 문서를 개별적으로 검색하여 결합합니다.
그러나 문서를 결합하고 중복을 제거하는 동안, 해당 문서의 중요성에 따라 순위를 매깁니다. RAG 퓨전 프로세스의 다이어그램적 표현을 보여드릴게요.
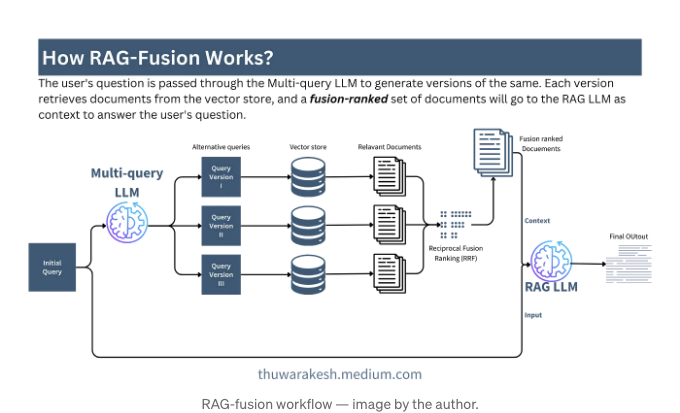
단순히 중복을 제거하는 것이 아니라 문서를 순위 시스템을 사용하여 정렬합니다. 상호 퓨전 순위(RRF)는 문서를 순위 매기는 간단하고 지능적인 방법입니다.
더 많은 쿼리 버전이 동일한 문서를 가장 관련성 높은 것으로 검색했다면, RRF는 그 문서를 높게 순위 지정할 것입니다. 만일 특정 문서가 한 쿼리 버전에서만 나타나고 그와 매우 다르다면, RRF는 이 문서를 낮게 순위 지정할 것입니다. 이렇게 함으로써 더 관련성 높은 정보를 얻고 우선순위를 정할 수 있습니다.
def reciprocal_rank_fusion(results: list[list], k=60):
""" 여러 개의 등수가 매겨진 문서 목록들을 가져와 RRF 공식에서 사용되는 선택적 매개변수 k를 사용하는 Reciprocal_rank_fusion 함수 """
fused_scores = {}
for docs in results:
for rank, doc in enumerate(docs):
doc_str = dumps(doc)
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
previous_score = fused_scores[doc_str]
fused_scores[doc_str] += 1 / (rank + k)
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
return reranked_results
# 4.1 RAG-fusion 프롬프팅
multi_query_prompt = """
당신은 AI 언어 어시스턴트입니다.
사용자 질문의 다른 버전 5개를 생성하는 것이 당신의 작업입니다.
이를 통해 사용자가 거리 기반 유사성 검색의 제한을 극복하는 데 도움이 됩니다.
이 대체 질문들을 새 줄로 구분해서 제공하세요.
질문: {question}
출력:
"""
multi_query_prompt_template = ChatPromptTemplate.from_template(multi_query_prompt)
retrieval_chain = (
multi_query_prompt_template
| llm
| StrOutputParser()
| (lambda x: x.split("\n"))
| retriever.map()
| reciprocal_rank_fusion
)
분해
일반적으로 곧바로 대답하는 것보다는 좀 더 복잡한 작업을 해결하는 데 훌륭한 방법은 문제를 조각내어 각각에 대해 답변하는 것입니다.
이건 LLM 기술만이 아니죠, 맞죠?
네, 우리는 초기 질문을 여러 하위 질문으로 분해하는 쿼리 분해를 시도하고 있어요. 이러한 하위 질문에 대한 답변은 초기 쿼리에 답변할 단서를 제공할 거예요.
![]()
다이어그램에서 보듯이, 우리는 각 하위 질문에 대한 관련 문서를 검색하고 별도로 답변합니다. 그런 다음 이 질문-답변 쌍을 최종 RAG-LLM에 전달해요. 이제 LLM에는 복잡한 문제를 해결할 더 상세한 정보가 있어요.
# 4.1 Decomposition prompting
decomposition_template = """AI 언어 도우미입니다.
다음 질문을 5개 하위 질문으로 나눠주세요.
이렇게 함으로써 사용자가 최종 답변을 점진적으로 구성하는 데 도움이 됩니다.
이들 대체 질문들을 새 줄로 구분하여 제공해주세요.
원래 질문: {question}
결과:
"""
decomposition_prompt_template = ChatPromptTemplate.from_template(decomposition_template)
def query_and_combine(questions: list[str]) -> str:
print(questions)
qa_pairs = []
for q in questions:
r = basic_rag_chain.invoke(q)
qa_pairs.append((q, r))
qa_pairs_str = "\n".join([f"Q: {q}\nA: {a}" for q, a in qa_pairs]).strip()
print(qa_pairs_str)
return qa_pairs_str
retrieval_chain = (
{"question": RunnablePassthrough()}
| decomposition_prompt_template
| llm
| StrOutputParser()
| (lambda x: x.split("\n"))
| query_and_combine
)
Final thoughts
데모 앱에서 프로덕션까지 많은 단계가 필요합니다. 하드웨어를 번역하는 것은 피할 수 없는 단계 중 하나입니다.
저희가 해결하는 문제는 복잡도가 다릅니다. 사용자의 불완전한 질문을 고려해야 합니다. 검색 과정의 단점을 고려해야 합니다. 이 모든 것들을 고려해야 합니다.
가장 적합한 쿼리 번역 기술을 선택하는 정확한 방법은 하나가 없어요. 실제 앱에서는 원하는 결과물을 얻기 위해 여러 기술을 결합해야 할 수도 있어요.