이 게시물은 Rafael Guedes와 공동 저작한 것입니다.
소개
대형 언어 모델(LLM)은 빠르게 발전해 왔습니다. 매달 새로운 모델이 개발되어 시장에서 현재의 최고 점수를 능가하기 위해 노력합니다. 이 건강한 경쟁은 질과 속도를 높이는 새로운 방법론을 만드는 데 도움이 됩니다. 게다가 회사들은 강력한 컴퓨팅 리소스 없이도 개인 또는 조직에서 접근할 수 있도록 작은 모델을 개발하는 데 주력하고 있습니다.
몇 주 전, 애플은 Worldwide Developers Conference에서 Apple Intelligence를 소개했습니다. 이것은 사용자가 텍스트를 작성하고 수정하고, 통지 사항을 우선 순위를 매기고 요약하며, 이미지를 생성하고, 앱 내 작업을 수행하는 데 도움이 되도록 세밀하게 조정된 여러 생성 모델의 집합입니다. 애플이 그 스위트에서 소개한 유일한 기반 및 독점 모델은 같은 컨퍼런스에서 소개되었습니다. 이것은 기기 내에서 실행되도록 설계된 소형 모델입니다. 하드웨어가 중요한 제약 조건이 되는 경우입니다. 애플의 경우, 해당 모델은 소스 코드가 비공개입니다. 우리가 아는 바로는, 애플이 공유한 결과에 따르면 7b 버전의 Gemma, Mistral 및 Llama 3와 동등한 약 30억 개의 파라미터 모델입니다.
애플의 새로운 모델이 흥미롭긴 하지만 테스트하거나 재사용할 수는 없습니다. 그래서 개발자들과 기업들이 새로운 제품과 서비스를 만들 때 사용할 수 있는 공개 모델에 더 관심이 있습니다. 오픈 LLMs와 오픈 소스 LLMs를 구분하는 것이 중요합니다. 역사적으로 오픈 소스 소프트웨어는 특정 라이선스에 따라 공개 사용이나 수정을 위해 소스 코드를 제공하는 컴퓨터 프로그램을 가리킵니다. LLMs의 경우, 훈련 데이터와 모델 가중치를 포함한 복잡성도 있습니다. 그래서 오픈 LLMs는 일반적으로 모델 가중치와 초기 코드를 공개합니다. 한편 오픈 소스 LLM은 훈련 과정의 모든 단계, 훈련 데이터 및 허용 라이선스를 포함하여 공유할 것입니다. 이는 다른 사람들이 모델을 사용하고 활용하며 추가적으로 배포할 수 있도록 해야 합니다. 그러나 요즘에는 대부분의 모델이 예를 들어 훈련 목적을 위해 사용된 데이터셋을 공개하지 않는 오픈 LLMs 범주에 속합니다. 구글의 Gemma, Mistral AI의 Mistral 및 Meta의 Llama도 이에 해당합니다.
이 기사에서는 이러한 작은 모델들을 구분하는 데 있어 Gemma에 더 깊이 관심을 가지고 분석합니다. Gemma는 구글에서 최근에 출시된 모델 중 하나입니다. 20억 파라미터와 70억 파라미터 버전으로 나뉘어 에지 디바이스에서 사용할 수 있도록 설계되었으며 Mistral과 Llama 3와 같은 최첨단 모델들을 능가하기를 목표로 합니다.
게다가, 우리는 Gemma, Llama 3 및 Mistral을 SQuAD라는 읽기 이해 데이터셋에 적용합니다. LLMs는 주어진 맥락에 기반한 구체적인 질문에 답변하는 것이 과제입니다. 우리는 추론 속도와 평균 답변 길이와 같은 양적 지표를 사용하여 그들의 성능을 평가합니다. 또한 우리는 [1]에서 제안된 상대적 답변 품질(RAQ) 프레임워크를 사용합니다. RAQ는 정답과의 상대적 정확도에 따라 답변을 순위를 매겨 구체적인 사용 사례에 대해 LLMs를 평가하는데 있어서 간견하고 실용적인 모델 성능 평가를 제공합니다.
언제나 코드는 우리의 GitHub에서 확인할 수 있어요.
Gemma: Gemini의 기반 텍스트 모델
Google은 강력한 클로즈 소스 모델인 Gemini을 기반으로 개발된 오픈 LLM인 Gemma [2]를 출시했어요.
Google은 모델의 추가적인 연구를 촉진하기 위해 사전 훈련 및 세밀 조정된 체크포인트를 공개했는데, 이는 두 가지 다른 크기로 이용 가능해요:
- 7B 모델은 GPU 또는 TPU에서 배포 및 추가 개발될 예정입니다.
- 2B 모델은 계산 제약을 해결하고 CPU 또는 장치 애플리케이션에서 사용할 수 있도록 설계되었습니다.
지마는 Llama 3 7B나 Mistral 7B와 같은 규모를 갖는 다른 오픈 모델과 비교하여 최첨단 성능을 달성할 것을 약속합니다. 이는 질문 응답, 상식적 추론, 수학/과학 및 코딩과 같은 다양한 도메인에서 이루어져야 합니다.
Gemma: 무엇이 새로운가요?
지마의 아키텍처는 8192 토큰의 컨텍스트 길이를 갖는 디코더 전용 [4] 트랜스포머 [5]에 기반합니다. 더 작게 만들기 위해 취한 접근 방식을 살펴보도록 하겠습니다.
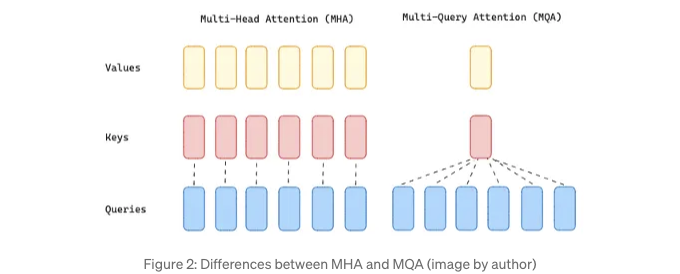
Multi-Query Attention
2B 모델은 Multi-Query Attention (MQA)를 활용하여 모든 쿼리, 키 및 값 헤드를 로드하는 데 필요한 메모리 리소스를 현저히 줄입니다. 이는 Multi-Head Attention (MHA) 접근 방식과 대조적입니다. MQA는 주의력 레이어에 여러 쿼리 헤드에 대해 단일 키와 값을 사용함으로써 이 메모리 감소를 달성합니다. 이는 Figure 3에서 설명한 대로 구현됩니다.
이 접근 방식을 통해 Gemma 2B를 메모리 리소스가 작은 장치에 배포할 수 있지만, 품질 저하와 훈련 불안정으로 이어질 수 있습니다. 따라서 저자들은 Llama 3의 방법을 따라 7B 버전에서 MHA를 사용하기로 결정했습니다.
RoPE 임베딩
트랜스포머는 순서에 민감한 특성이 있기 때문에 위치 임베딩을 필요로 합니다. 이는 위치 정보를 제공하지 않으면, 트랜스포머는 단어는 같지만 순서와 의미가 다른 문장을 동일하게 처리할 것입니다. 예를 들어,
위치 정보는 일반적으로 사인과 코사인 두 개의 함수를 사용하여 표현됩니다. 그런 다음, 각 위치에 대한 고유한 위치 임베딩이 생성됩니다. 이는 위치, 토큰 임베딩 차원 및 모델 차원을 기반으로 시퀀스 내 각 위치에 대해 생성됩니다.
따라서 위치 정보를 추가하는 것은 텍스트를 올바르게 처리할 수 있도록 트랜스포머를 가능하게 하는 데 중요합니다. 초기 트랜스포머 아키텍처는 절대 위치 임베딩을 사용했는데, 여기서 위치의 벡터 표현이 토큰의 벡터 표현에 추가되었습니다.

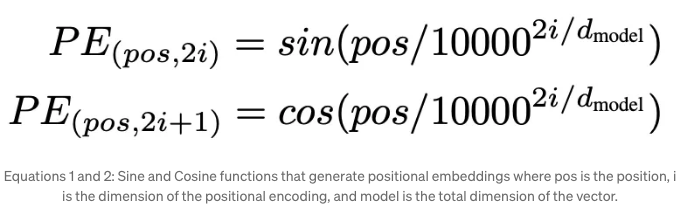
절대 위치 임베딩의 문제는 토큰 간 상대 거리를 명시적으로 인코딩하지 않는다는 것입니다. 사인 및 코사인 함수를 사용하여 위치 정보를 캡처하지만 이러한 임베딩은 각 위치에 대해 독립적으로 계산됩니다. 이는 모델이 시퀀스 내의 다른 위치들의 근접성이나 관계적 중요성을 본질적으로 이해하지 못한다는 것을 의미합니다. 예를 들어, 사인 함수의 특성 때문에 위치 1과 2의 토큰에 대한 임베딩이 유사해 보일 수 있지만, 모델은 이러한 위치가 인접해 있는지 명시적으로 인식하지 않습니다.
이로 인해 모델은 위치 1과 2에 있는 토큰 간의 관계를 위치 1과 500에 있는 토큰 간의 관계와 구분하지 못할 수 있습니다. 자연어 처리에서 문장 내에서 서로 가까운 단어는 종종 더 많은 문맥을 공유하거나 더 강한 의미론적 또는 구문적 관계를 갖는 경향이 있습니다. 절대 위치 임베딩은 이 세부 사항을 완전히 포착하지 못할 수 있습니다. 이는 먼 거리 종속성이나 언어의 계층 구조를 포착하는 데 제한이 생길 수 있습니다.

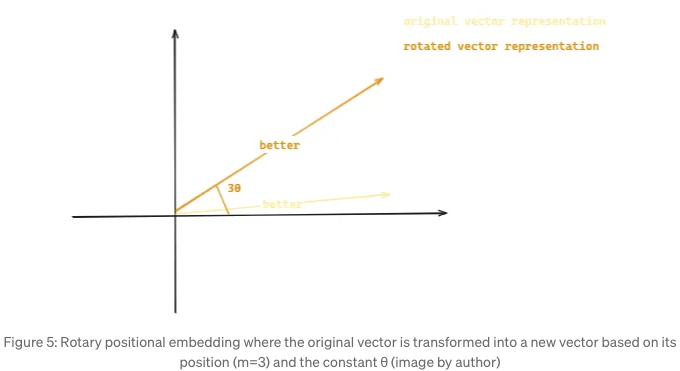
로터리 위치 임베딩(RoPE) [6]은 이 문제를 해결하기 위해 토큰 임베딩을 순서대로 회전시켜 토큰들의 상대적 위치를 모델링합니다.
이전 예시 'Gemma is better than Llama'를 사용하고, 각 단어를 2D 벡터로 표현된 토큰으로 간주해 보겠습니다. 단어 better는 원래 벡터에서 위치 m과 상수 각도 θ에 따라 회전한 2D 벡터로 표현됩니다. Figure 5에 표시된 것처럼요.
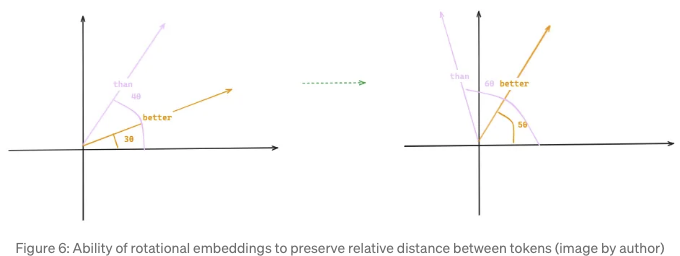
이 접근 방식은 회전 변환을 통해 시퀀스 내의 위치에 관계없이 벡터 간 유사성을 유지하기 때문에 토큰 간 상대적 거리를 보존합니다. 예를 들어, 두 단어를 원래 문장에 추가하여 'The LLM Gemma is better than Llama'로 만들면, better와 than의 위치가 (3 & 4)에서 (5 & 6)으로 변경됩니다. 그러나 회전 각도가 일정하게 유지되기 때문에 이러한 벡터 간 유사성(점곱으로 측정)이 동일하게 유지되어 일관된 상대적 위치 지정을 보장합니다.
GeGLU 활성화 함수
저자들은 전통적인 ReLU 활성화 함수를 GeGLU라 불리는 Gated Linear Unit(GLU)의 변형으로 대체했는데, 다른 연구[7]에서 LLM이 생성한 출력의 품질을 향상시킨다고 보여졌기 때문입니다.
ReLU와 GeGLU 사이에 두 가지 차이점이 있습니다:
- 활성화 함수 — GeGLU는 ReLU와 다르게 가우시안 에러 선형 유닛 (GELU) [8] 함수를 사용합니다. 이 함수는 뉴런 입력 x를 정규 분포의 누적 분포 함수로 곱하는 점에서 ReLU와 다릅니다. 이 경우, x가 감소함에 따라 x가 삭제될 확률이 더 높아집니다.
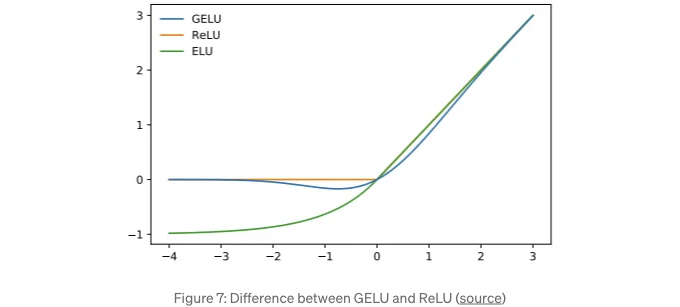
- 시그모이드 활성화 — 간단한 ReLU 또는 GELU 활성화 함수가 숨겨진 표현 x와 두 행렬 (W1 및 W2)로 표현되는 두 선형 변환 사이에 적용됩니다. GeGLU의 게이팅 변형은 하나의 구성요소에 게이팅 매커니즘 (시그모이드)을 적용합니다. 식 3에서 보여지듯이.

정규화기 위치
원래 Transformer 아키텍처에 대한 마지막 수정은 도형 8에 표시되어 있습니다. 저자는 각 트랜스포머 하위 레이어의 입력과 출력을 모두 정규화하여 훈련 안정성을 향상시킵니다. 이는 원래 논문에서는 출력만 정규화했던 것과는 반대입니다.
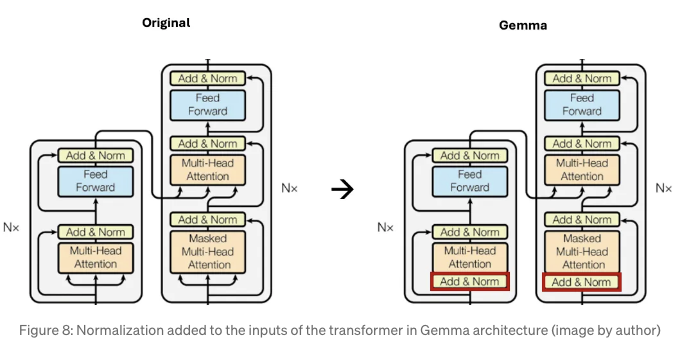
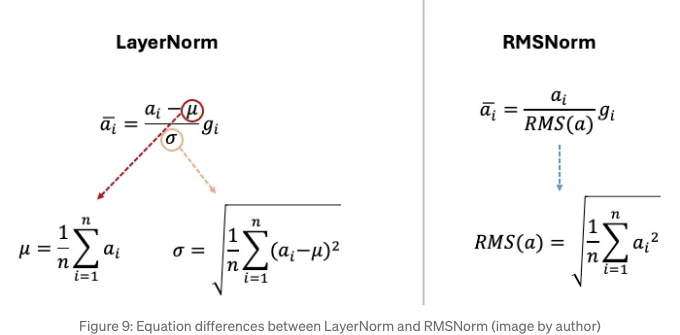
그들은 전통적인 LayerNorm 함수를 RMSNorm [8]로 대체했습니다. 이는 학습 안정성 향상을 유지하면서 계산상으로 더 효율적이며 모델 수렴을 돕습니다.
RMSNorm은 LayerNorm의 이득이 재조정 불변성(re-scaling invariance)에서 비롯된다는 점을 보여줌으로써 더 나은 효율성을 달성합니다. 이것은 입력을 일정한 배율로 변환해도 정규화 과정의 출력이 변경되지 않는다는 것을 의미합니다. 다시 말해, 모든 입력을 일정한 상수로 곱해도 정규화된 출력에는 영향이 없습니다. 중심 재조정 불변성(re-centering invariance)은 모든 입력에 일정한 값을 더한 경우에도 정규화 과정의 출력이 변경되지 않는다는 것을 의미합니다. 즉, 모든 입력을 일정량만큼 이동시켜도 정규화된 출력에는 영향이 없습니다. 이 연구 결과는 평균을 계산하는 오버헤드를 제거할 수 있도록 하여 RMSNorm을 더 간단하고 효율적으로 만듭니다.
Mistral AI 대 Meta 대 Google: Gemma 7B 대 Llama 3 7B 대 Mistral 7B 비교
이 섹션에서는 Gemma 7B, Mistral 7B 및 Llama 3 7B의 3개의 LLM을 테스트하였습니다. 우리는 SQuAD(여기에서 찾을 수 있음) 라이선스 CC BY-SA 4.0에 따라 만들어진 질의응답 데이터셋을 사용했습니다. 이 데이터셋은 위키피디아 기사에 대한 질문으로 구성된 독해 이해 데이터셋입니다. 문맥에 따라 모델은 질문에 대한 정확한 답변을 검색해야 합니다. 우리의 사용 사례에 대한 3가지 더 중요한 필드는:
- question - 모델이 답변해야 할 질문.
- context - 모델이 답을 추출해야 하는 배경 정보.
- answers - 질문에 대한 텍스트 답변입니다.
평가 프로세스는 두 가지 양적 지표로 구성됩니다:
- 초당 단어 수 - 추론 속도를 평가합니다.
- 단어 - 답변의 길이를 평가합니다.
우리 사용 사례 모델의 정확성을 평가하기 위해 RAQ [1]를 사용합니다. RAQ는 모든 LLM의 답변을 지면 진실 답변에 얼마나 가까운지에 따라 독립 LLM을 기반으로 순위를 매깁니다.
먼저 CPU에서 실행할 수 있도록 모델을 .gguf 형식으로 다운로드하여 model/ 폴더에 배치합니다.
각 모델의 instruct 버전을 사용했으며 4비트 양자화를 사용했습니다:
- Mistral-7B-Instruct의 mistral-7b-instruct-v0.1.Q4_K_M.gguf
- Meta-Llama-3-8B-Instruct의 Meta-Llama-3-8B-Instruct-Q4_K_M.gguf
- gemma-7b-it의 gemma-7b-it-Q4_K_M.gguf
그 다음에는 모든 라이브러리 및 원하는 모델을 받는 생성기(generator)를 가져옵니다.
import os
import seaborn as sns
import matplotlib.pyplot as plt
import scikit_posthocs as sp
import pandas as pd
import utils
from dotenv import load_dotenv
from datasets import load_dataset
from generator.generator import Generator
llama = Generator(model='llama')
mistral = Generator(model='mistral')
gemma = Generator(model='gemma')
load_dotenv('env/var.env')
이 클래스는 config.yaml 파일에 정의된 모델 매개변수를 가져오는 것을 담당하며, 다음과 같은 특성을 갖습니다: context_length가 1024, temperature가 0.7, max_tokens가 2000.
generator: llama: llm_path: "model/Meta-llama-3-8B-Instruct-Q4_K_M.gguf";
mistral: llm_path: "model/mistral-7b-instruct-v0.1.Q4_K_M.gguf";
gemma: llm_path: "model/gemma-7b-it-Q4_K_M.gguf";
context_length: 1024;
temperature: 0.7;
max_tokens: 2000;
프롬프트 템플릿을 생성합니다. 이 템플릿은 쿼리와 컨텍스트를 형식화하여 LLM에 전달하기 전에 응답을 받습니다.
from langchain import PromptTemplate
from langchain.chains import LLMChain
from langchain.llms import LlamaCpp
from base.config import Config
class Generator(Config):
"""질문과 컨텍스트를 기반으로 답변을 제공하는 Generator 또는 LLM"""
def __init__(self, model) -> None:
super().__init__()
# 템플릿
self.template = """
다음 컨텍스트 조각을 사용하여 마지막 부분에 있는 질문에 답변하십시오.
{context}
질문: {question}
답변:
"""
# 로컬 파일에서 llm 로드
self.llm = LlamaCpp(
model_path=f"{self.parent_path}/{self.config['generator'][model]['llm_path']}",
n_ctx=self.config["generator"]["context_length"],
temperature=self.config["generator"]["temperature"],
)
# 프롬프트 템플릿 생성
self.prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
def get_answer(self, context: str, question: str) -> str:
"""
컨텍스트와 사용자의 질문을 기반으로 llm에서 답변을 가져옵니다.
Args:
context: 가장 유사한 문서 검색
question: 사용자의 질문
Returns:
llm 답변
"""
query_llm = LLMChain(
llm=self.llm,
prompt=self.prompt,
llm_kwargs={"max_tokens": self.config["generator"]["max_tokens"]},
)
return query_llm.run({"context": context, "question": question})
LLM을 로드하고, HuggingFace에서 SQuAD 데이터셋을 불러와 질문 주제의 충분한 다양성을 보장하기 위해 섞습니다.
squad = load_dataset("squad", (split = "train"));
squad = squad.shuffle();
이제, 60개의 질문과 콘텍스트를 순회하며 앞서 언급된 메트릭을 기록할 수 있습니다.
for i in range(60):
context = squad[i]['context']
query = squad[i]['question']
answer = squad[i]['answers']['text'][0]
# Llama
answer_llama, words_per_second, words = utils.get_llm_response(llama, context, query)
llama_metrics["words_per_second"].append(words_per_second)
llama_metrics["words"].append(words)
# mistral
answer_mistral, words_per_second, words = utils.get_llm_response(mistral, context, query)
mistral_metrics["words_per_second"].append(words_per_second)
mistral_metrics["words"].append(words)
# gemma
answer_gemma, words_per_second, words = utils.get_llm_response(gemma, context, query)
gemma_metrics["words_per_second"].append(words_per_second)
gemma_metrics["words"].append(words)
# GPT-3.5 rank
llm_answers_dict = {'llama': answer_llama, 'mistral': answer_mistral, 'gemma': answer_gemma}
rank = utils.get_gpt_rank(answer, llm_answers_dict, os.getenv("OPENAI_API_KEY"))
llama_metrics["rank"].append(rank.index('1')+1)
mistral_metrics["rank"].append(rank.index('2')+1)
gemma_metrics["rank"].append(rank.index('3')+1)
함수 get_llm_response은 불러온 LLM, 콘텍스트, 질문을 받아 LLM 답변 및 양적인 메트릭을 반환하는 역할을 합니다.
def get_llm_response(model: Generator, context: str, query: str) -> Tuple[str, int, int]:
"""
주어진 콘텍스트와 질문을 기반으로 주어진 LLM에서 답변을 생성합니다.
답변 및 초당 단어 수 및 총 단어 수를 반환합니다.
인수:
model: LLM
context: 콘텍스트 데이터
query: 질문
반환:
답변, 초당 단어 수, 단어 수
"""
init_time = time.time()
answer_llm = model.get_answer(context, query)
total_time = time.time() - init_time
words_per_second = len(re.sub("[^a-zA-Z']+", ' ', answer_llm).split())/total_time
words = len(re.sub("[^a-zA-Z']+", ' ', answer_llm).split())
return answer_llm, words_per_second, words
우리는 Llama 3이 초당 약 0.7 단어를 생산하여 Mistral과 Gemma보다 더 빠름을 알 수 있습니다. Mistral은 약 0.26, Gemma는 약 0.4 단어를 생산합니다. 답변의 길이 측면에서도 Llama 3이 Mistral과 Gemma보다 긴 답변을 생산하는데, 평균 답변 길이는 Mistral의 20 단어, Gemma의 50 단어에 비해 148 단어입니다. 마지막으로 RAQ를 기반으로 Mistral이 평균 순위 약 1.81로 가장 우수하며, Gemma는 평균 2.05로 그 뒤를 이었고, Llama 3는 약 2.1의 평균 순위로 성능이 더 낮은 것으로 나타났습니다.
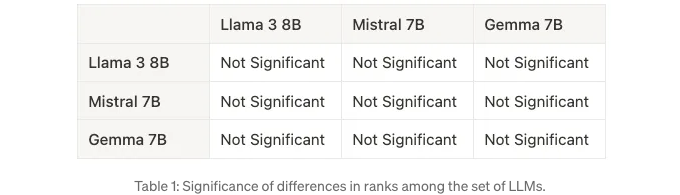
RAQ 프레임워크에는 관측된 차이가 유의한지 이해하기 위한 통계적 검정도 포함되어 있습니다. 테이블 1은 서로 다른 언어 모델의 성능을 비교하는 Dunn 사 후 검정의 결과를 보여줍니다. 각 셀은 해당 모델 간의 성능 차이가 5% 유의수준에서 통계적으로 유의한지를 나타냅니다. "유의함"은 통계적으로 유의한 차이 (p-값 ≤ 0.05)를 나타내며, "유의하지 않음"은 통계적으로 유의한 차이가 없음을 나타냅니다 (p-값 ` 0.05). 선택한 유의수준에 대해 Dunn 검정 결과는 모델 간의 성능 차이가 유의하지 않음을 보여줍니다.
p_values = sp.posthoc_dunn(
[Llama_metrics["rank"], mistral_metrics["rank"], gemma_metrics["rank"]],
(p_adjust = "holm")
);
p_values > 0.05;
일부 예시를 질적으로 평가하는 것은 항상 중요합니다. 아래에는 뉴 헤이븐(New Haven)에서 'Power House Day'가 언제 기념하는지에 대한 3개 모델의 답변이 있습니다.
세 모델 모두 정확한 답변을 제공했습니다. Llama 3와 Gemma는 더 완전한 답변을 제공했지만, Mistral은 좀 더 간결했습니다.
결론
기기 내 모델은 낮은 계산 자원을 가진 장치에서 강력한 LLM을 이용할 수 있는 좋은 기회를 제공합니다. Apple과 Google은 더 작고 효율적인 모델을 개발하여 이러한 요구를 충족시키는 데 적극적으로 노력하고 있습니다. 이를 통해 더 많은 사람들이 일상 생활에서 고급 AI의 혜택을 누릴 수 있도록 도와줍니다.
이 기사에서는 Google이 개발한 오픈 LLM인 Gemma를 탐구했습니다. 이 LLM은 기존 Transformer 아키텍처에 Multi-Query Attention(2B 버전), positional encoding을 위한 RoPE 임베딩, 활성화 함수로 GeGLU 및 입력 정규화라는 네 가지 혁신적인 기능을 소개했습니다.
우리는 Gemma의 성능을 독해 데이터셋에서 Llama 3 및 Mistral과 비교했습니다. Gemma가 Mistral보다 더 많은 단어를 초당 생성하고 더 긴 답변을 작성했지만, 이러한 지표에서 Llama 3를 능가하지는 못했습니다. RAQ 프레임워크를 사용하여 세 모델의 정확도를 평가했습니다. Mistral이 가장 좋은 결과를 보였고, Gemma가 그 뒤를 이었지만, 이러한 차이는 통계적으로 유의하지 않았습니다. 따라서 우리는 읽기 이해와 관련된 사용 사례에 적용할 때 3개 모델이 유사하게 수행된다고 할 수 있습니다.
나에 대해
인공지능 분야의 시리얼 창업가이자 리더입니다. 비즈니스를 위한 인공지능 제품을 개발하고, 인공지능 중심의 스타트업에 투자합니다.
Founder @ ZAAI | LinkedIn | X/Twitter
참고 자료
[1] Luís Roque, Rafael Guedes. Research to Production: Relative Answer Quality (RAQ) and NVIDIA NIM. https://medium.com/@luisroque/research-to-production-relative-answer-quality-raq-and-nvidia-nim-15ce0c45b3b6, 2024.
[2] Gemma Team, Google DeepMind. Gemma: Open Models Based on Gemini Research and Technology, 2023.
[3] Gemini 팀. Gemini: 고성능 다중 모달 모델 가족, 2023.
[4] Noam Shazeer. 빠른 트랜스포머 디코딩: 하나의 쓰기 헤드만 필요, arXiv:1911.02150, 2019.
[5] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. 주의를 모두 할 것: arXiv:1706.03762, 2017.
[6] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, Yunfeng Liu. RoFormer: 회전 위치 임베딩으로 개선된 트랜스포머, arXiv:2104.09864, 2021.
[7] Noam Shazeer. GLU Variants Improve Transformer. arXiv:2002.05202, 2020.
[8] Dan Hendrycks, Kevin Gimpel. Gaussian Error Linear Units (GELUs). arXiv:1606.08415, 2016.
[9] Biao Zhang, Rico Sennrich. Root Mean Square Layer Normalization. arXiv:1910.07467, 2019.