
이 글을 읽고 있는 대부분은 H100과 같은 고급 AI GPU에 액세스할 수 없는 AI 애호가일 것입니다. 대부분은 소비자급 GPU에서 모델을 훈련하고 겨우 1개의 에포크를 완료하기까지 기다리는 고난을 알고 있을 것입니다.
저의 석사 논문 작성 중에, 초기 시간의 4.65%로만 기간을 줄일 수 있었거나 다른 말로, 속도를 2153% 향상시켰습니다.
배경 이야기
제 학위 논문에서 압축된 데이터 세트는 472 GB였고, 이 데이터로 32개의 모델을 훈련하기로 계획했습니다. 모든 것을 설정하고 훈련 파이프라인을 테스트한 후, 사용한 2080Ti GPU에서 한 번의 훈련 반복에 10시간 40분 4초가 걸리는 것으로 판단했습니다... 그리고 적어도 유용한 결과를 얻기 위해서는 최소 50번의 반복이 필요할 것으로 예상했습니다. 이를 생각해보면: 32개 모델 x 10.7시간 x 50번 반복 = 713.33일이 소요됩니다.
전략 I — 더 많은 GPU
이 전략은 AI 애호가들이 한정된 컴퓨팅 능력에 대한 노력을 강조한 뒤에는 조금 모순적으로 보일 수 있습니다. 하지만 사실을 말하자면, 우리는 AI에 대해 얘기하고 있습니다. 이 공간에서 작업을 완료하고 싶다면 어느 정도 비용이 들어갈 수밖에 없습니다. 그러나 총 €480에 4개의 리퍼비시된 RTX 2080 TI와 약 €6-7천에 낮은 등급의 AI GPU 사이에는 상당한 차이가 있습니다.
이야기를 다시 하면, 저는 멀티노드 Slurm 클러스터 구성에서 4개의 RTX 2080 TI를 활용하기로 결정했습니다. 이는 4개의 PC를 각각 하나의 GPU가 장착된 상태로 사용하는 것을 의미합니다. 처음에는 상당한 부담이 될 수 있지만, 궁극적으로 이를 설정하는 것은 가치가 있습니다. 한 가지 이점은 현재 필요하지 않은 노드를 끌 수 있고 전력을 절약할 수 있다는 것입니다. 또 다른 이점은 각 PC를 게임, 포토샵, 랜더링 또는 기타 GPU 집중적인 작업을 위해 개별적으로 사용할 수 있다는 것입니다.
설정이 모두 완료되고 구성이 완료된 후에 PyTorch를 사용한 데이터 병렬 처리로 첫 번째 속도 향상률이 363% 만큼 있었어요. 더욱 쉽게 하기 위해 코드를 PyTorch-lightning으로 이식하여 트레이너가 데이터 분배를 처리할 수 있도록 했어요.
간단한 PyTorch-lightning 예시를 보여드릴게요:
trainer_config = {
"accelerator": "gpu",
"precision": "32",
"devices": 1, # 노드 당 GPU 수
"num_nodes": 4, # 노드 수
"max_epochs": 50
}
mock_data_config_train = {
'batch_size': 32,
'shuffle': True,
'num_workers': 4, # 노드 당 GPU의 4배
}
mock_data_config_test = {
'batch_size': 32,
'shuffle': False,
'num_workers': 4, # 노드 당 GPU의 4배
}
trainer = pl.Trainer(**trainer_config)
train_dl = DataLoader(train_data, **mock_data_config_train)
valid_dl = DataLoader(valid_data, **mock_data_config_test)
model = ... # 여러분의 PyTorch-lightning으로 래핑된 모델
trainer.fit(
model=lightning_model,
train_dataloaders=train_dl,
val_dataloaders=validation_dl
)
이제 간단한 bash에서 Slurm 제출 스크립트를 보겠습니다:
#!/bin/bash -l
# SLURM 제출 스크립트
#SBATCH --nodes=4
#SBATCH --gres=gpu:1
#SBATCH --ntasks-per-node=1
#SBATCH --output=var/logs/run.out
. /opt/conda/etc/profile.d/conda.sh
conda activate ddp_env
srun python /var/train/train.py # 위의 스크립트 실행
전략 II — 데이터 처리 최적화하기
훈련 속도를 더 최적화하기 위해 데이터 로더를 살펴보았어요. 비디오 작업을 하고 있어서 모델이 데이터를 훈련하기 전에 많은 데이터를 처리해야 했어요. 데이터 처리는 훈련과 병렬로 진행되었지만, 데이터 양과 처리 복잡성으로 인해 훈련이 크게 늦어졌어요 (당연한 이야기죠).
그게 무슨 말인지 알려드릴게요... 그림 1에서 볼 수 있듯이 데이터 처리가 훈련에 미치는 영향이 얼마나 큰지 보여드릴게요. 각 노란색 블록은 처리된 데이터 배치를 나타내고, 각 파란색 블록은 한 번의 훈련 스텝을 나타내요.
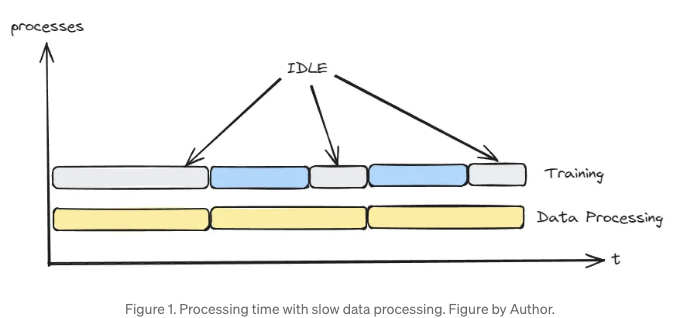
배치 준비가 이전 학습 단계보다 더 오래 걸리면 모델은 다음 배치가 준비될 때까지 기다려야 합니다.
이상적으로는 데이터 처리가 학습 단계만큼 빨라야 원활한 학습 과정이 보장됩니다. 이것은 그림 2에서 확인할 수 있습니다.
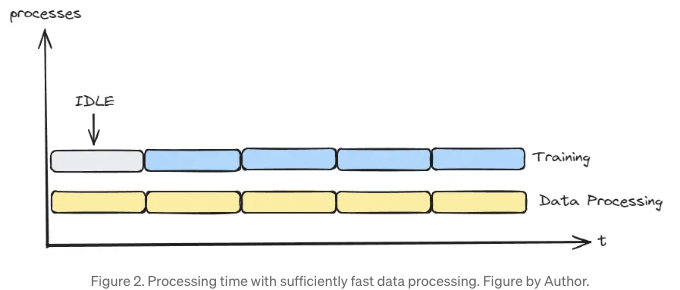
당신의 데이터 처리가 병목이 되었는지 확인하려면 기차 데이터 로더와 테스트 데이터 로더가 하나의 훈련 단계에 얼마나 걸리는지 비교해보세요. 그들이 대략적으로 같은 기간을 소요한다면, 데이터 로더는 여러분의 파이프라인에서 병목이 아닙니다.
만약 데이터 로더가 병목이라면, 첫 번째 단계는 추가 전처리 단계로 수행될 수 있는 구성 요소를 찾아내는 것입니다.
정확히 하나씩 알아봅시다
나는 훈련한 모델들의 데이터 로더에서, 사전 학습된 MCTNN 얼굴 인식 모델을 사용하여 얼굴을 30% 여백으로 자르고, 그런 다음 각 이미지에서 얼굴 랜드마크를 추출했습니다. 이러한 얼굴 랜드마크는 볼록 다각형 및 관심 영역을 계산하는 데 사용되어 특정 얼굴 특징에 전문화된 데이터 증강을 적용했습니다. 이 증강이 완료되면 결과 이미지는 더 일반적인 Albumentation 변환을 더 적용하기 위해 두 번째 증강 파이프라인에서 처리되었습니다. 이 설명만으로도 알 수 있듯이, 데이터 처리 함수는 꽤 복잡하고 계산적으로 요구됩니다.
데이터 작업자 프로세스 소요 시간을 줄이기 위해 가능한 모든 것을 미리 계산하여 가공을 적용할 준비가 된 상태로 새로운 parquet 데이터 세트에 원시 값들을 저장했습니다. 이 선행 계산은 한 노드에서 완료하는 데 대략 10시간이 걸렸어요. 새로운 디자인은 아래의 그림 3에서 확인하실 수 있어요.
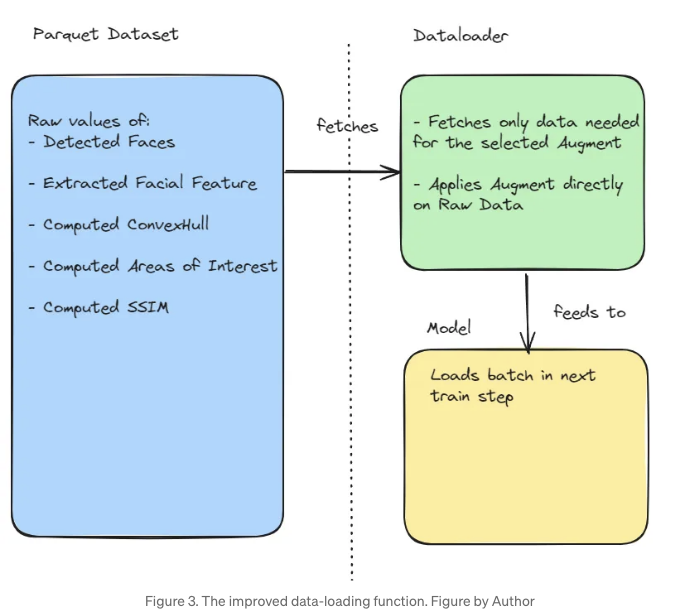
이 새로운 디자인은 한 에포크에 대한 초기 기간 대비 1329%의 속도 향상을 가져왔습니다.
전략 III — ZeRO Optimizer (DeepSpeed)
이번에 한 에포크에 필요한 시간을 더 줄이기 위한 다음 단계는 Microsoft에서 개발한 DeepSpeed 라이브러리였어요. 이 라이브러리는 PyTorch-lightning과도 밀접하게 통합되어 있어요. 이 라이브러리에는 여러 사전 정의된 구성이 제공되죠:
- DeepSpeed ZeRO Stage 1 — Shard optimizer states
- DeepSpeed ZeRO Stage 2 — Shard optimizer states and gradients
- DeepSpeed ZeRO Stage 3 — Shard optimizer states, gradients, parameters and optionally activations
- DeepSpeed ZeRO Stage 2와 Stage 3은 추가적인 메모리 최적화를 위한 오프로딩 구성이 함께 제공돼요
이제 아마도 "메모리 최적화? 어떻게 도움이 될까요?"라는 의문이 들 수 있어요. 더 낮은 메모리 소비는 학습 중에 더 큰 배치 크기를 사용할 수 있어 GPU로 데이터를 더 적게 전송해야 한다는 뜻이에요. 그런데 진정한 속도 향상은 fp16로 전환한 후에 일어났어요. DeepSpeed 라이브러리가 강력히 추천한 것이죠. PyTorch-lightning 프레임워크를 사용하여 코드에 이러한 변경 사항을 적용하는 것은 간단하며 코드 한 줄만 추가하면 돼요.
trainer_config = {
"accelerator": "gpu",
"precision": "16", # 변경된 정밀도
"devices": 1, # 노드 당 GPU 개수
"num_nodes": 4, # 노드 수
"strategy": "deepspeed_stage_2", # DeepSpeed Stage 추가
"max_epochs": 50
}
mock_data_config_train = {
'batch_size': 32,
'shuffle': True,
'num_workers': 4, # 노드 당 4배의 GPU
}
mock_data_config_test = {
'batch_size': 32,
'shuffle': False,
'num_workers': 4, # 노드 당 4배의 GPU
}
trainer = pl.Trainer(**trainer_config)
train_dl = DataLoader(train_data, **mock_data_config_train)
valid_dl = DataLoader(valid_data, **mock_data_config_test)
model = ... # PyTorch-lightning으로 랩핑된 모델
trainer.fit(
model=lightning_model,
train_dataloaders=train_dl,
val_dataloaders=validation_dl
)
이러한 변경 사항 둘 다 속도를 최종 값인 2153%로 증가시켰어요.
결론
모든 최적화 작업을 거친 결과는 다음과 같이 요약할 수 있어요:
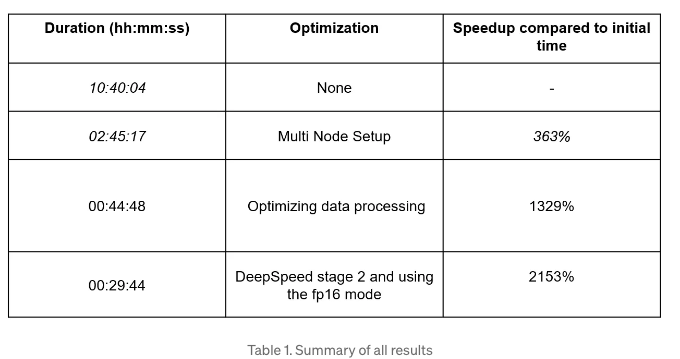
위에서 설명한 모든 전략을 활용하여, 저는 마스터 논문 프로젝트를 한 달 안에 완료할 수 있었어요. 좀 더 정확히 말하면, 33일이 걸렸습니다. 이전에는 713일이 걸렸던 프로젝트를 완성한 것이죠.
이 기사의 향상은 제 사용 사례에 특화되어 있을 수 있고, 모든 경우에 완전히 적용되지는 않을 수 있지만, 가능한 속도 향상 전략을 하나 이상 적용함으로써 달성할 수 있는 가능성을 보여 주는 좋은 예시입니다.
이 기사를 읽어 주셔서 감사합니다! 즐겁거나 유익하다는 생각이 드신다면, 자유롭게 반응해 주시고 의견을 말씀해 주세요. 여러분의 피드백은 소중하며, 여러분의 의견과 질문에 참여하는 것을 고대하며 기대하고 있어요. 문의 사항이나 제안이 있다면 망설이지 마시고 공유해 주세요. 여러분을 도와드리고 여러분의 소중한 의견을 기다리고 있어요.
감사합니다, Alex