큰 언어 모델(LLMs)은 당신이 생각하는 것과는 다릅니다. 속지마세요. LLMs는 멍청하고, 아주 멍청합니다. 사실, 그들은 인간보다는 데이터베이스에 더 가깝습니다.
그 이유는 인공 지능이 아직 지성을 정복하기 위한 매우 첫걸음이라는 점입니다... 만약에 가능하다면요.
최고의 가스라이팅
전선 인공지능 구축은 비용이 많이 듭니다. 전선 인공지능은 많은 위험 자본이 필요합니다. 전선 인공지능 연구소는 수십억을 모집합니다. 전선 인공지능은 기대에 미치지 못합니다. 전선 인공지능 연구소는 수십억을 정당화하기 위해 거짓말을 합니다.
이게 현재의 인공지능 산업이에요.
LLM은 추론을 할 수 없어요.
지능적이기 위해서는 추론을 할 수 있어야 해요. 하지만 LLMs는 추론을 못해요. 거의 못 하죠.
그렇다면, LLMs는 무엇을 할까요? 대부분의 경우, LLMs는 토를 합니다.
일반적인 MMLU와 같은 벤치마크는 “LLM의 지능을 얼마나 측정하는가”를 측정하는 가장 인기 있는 방법이지만, 대부분의 내용은 간단한 기억력으로 완벽하게 해결될 수 있습니다.
그러나 기억력으로 16세의 수학을 하는 10세 소녀는 수학을 이해한다고 할 수 없는 것처럼, LLM들도 자신의 지능을 가짜로 만드는 데 탁월합니다.
그렇다면, 우리는 LLM이 정말 얼마나 똑똑한지 어떻게 측정할까요? 간단하게 그들을 기억력만으로는 구할 수 없는 상황에서 테스트하면 됩니다. 그렇게 하면 현실이 드러납니다:
ARC-AGI부터 이상한 나라의 앨리스까지
LLM의 문제 해결 능력을 테스트하는 한 가지 훌륭한 방법은 ARC-AGI 벤치마크입니다. 이 벤치마크는 IQ 테스트와 매우 유사하며, 모델이 주어진 패턴에 대한 작은 예제 하위 집합을 보고 다음 시도에서 해당 패턴을 완성할 수 있는 기회를 제공합니다.
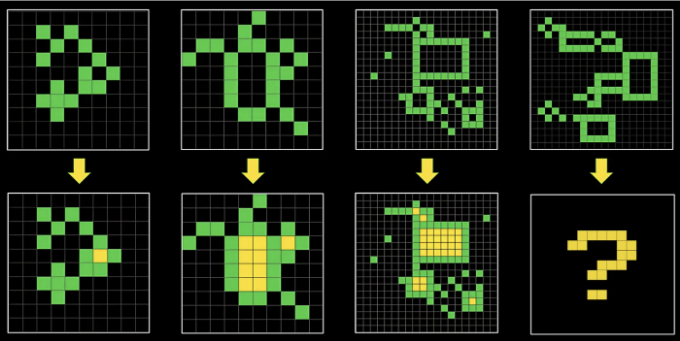
LLM에게는 매우 어려운 문제인데, 이는 두 가지 이유 때문입니다:
- 이는 그들이 이전에 본 적이 없는 연습문제에 기반하고 있어서 기억 속에서 해답을 찾아야 합니다.
- 이는 저샷 연습문제이며, 모델이 정답을 일반화하기 위한 소수의 예제만 가지고 있습니다.
물론, LLMs는 일반적인 인간이 매우 쉽게 해결할 수 있는 이러한 테스트에서 불성실하게 실패합니다. 하지만 왜 그럴까요?
또 다시, 두 가지 이유 때문입니다:
- 그들이 메모리를 사용할 수 없다면, 그들은 실패하게 됩니다.
- 인간과 달리, 그들은 많은 예시를 필요로 하는 샘플 효율성이 낮습니다. 새로운 패턴을 배우려면 많은 예제가 필요합니다.
그러므로, 우리가 지안 피아제의 지능에 대한 정의를 살펴보면: "지능은 당신이 뭘 해야 할지 모를 때 사용하는 것"이라면, 현재 AI에는 지능이 존재하지 않습니다.
그러나 경험이나 지식이 없는 상황에서 새로운 문제를 해결하지 못하는 것(“알려지지 않은 미지” 해결)이 그들의 유일한 문제는 아닙니다. 그들은 이미 알려진 지식에 대해 추론하는 것에도 능숙하지 않습니다(“알려진 지식” 해결).
앨리스 인 원더랜드 테스트
예를 들어, 모델이 이전에 명시된 사실에 기반하여 사실을 추론해야 하는 간단한 귀납적 추론 테스트 한 가지만으로 이러한 모델들을 부끄러운 상황에 처하게 할 수 있습니다.
그리고 저를 믿지 않아도 괜찮습니다. 직접 해보세요.
유명한 '에일리스 천국' 테스트의 한 예시를 사용하여 테스트한 결과, 간단한 추론 예시 세트에 대한 이 모델(GPT-4o)은 놀랍게도 옳바른 결론을 도출할 능력이 없다는 것이 입증되었습니다. 에일리스가 '자매 그룹'의 일부로 포함되어야 한다는 것을 추론할 수 없다는 한계가 있습니다.
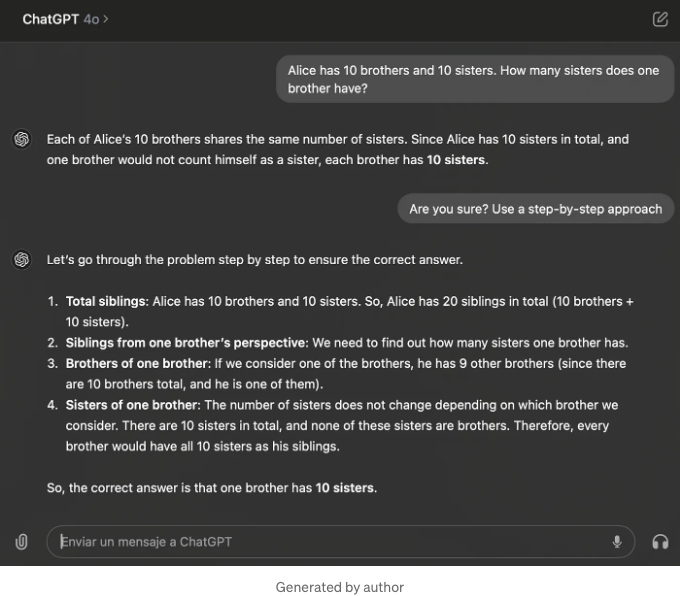
이것은 중요한 깨달음입니다. 옳바른 답을 추론하는 데 필요한 모든 정보를 갖고 있음에도, 어떤 의미 없는 프롬프트 엔지니어링 토끼굴을 탐구하지 않는 한 여전히 찾아낼 수 없다는 것입니다.
그리고 심지어 그것도 실패합니다.

And again.
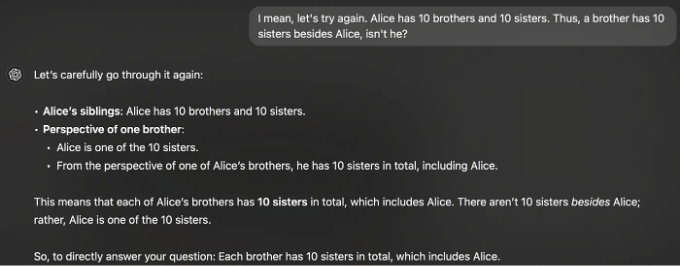
Long story short, most of these models can’t apply even the simplest of reasoning chains over their data, signaling once again that they are simply regurgitating past patterns.
그래서 이들이 "데이터베이스" 인 이유입니다. 단어 패턴 (문제에 대한 가능한 해결책을 생성하기 위해 단어가 서로 어떻게 따라가는지) 이 이전에 본 적이 있을 때에만 올바르게 작동합니다.
그들이 가지고 있는 모든 정보를 갖고 있더라도, 그것들은 알려진 사실로부터 사실을 추론할 수 없습니다... 마치 데이터베이스가 할 수 없는 것과 마찬가지입니다.
하지만 이것은 이 모델들이 데이터베이스보다 똑똑하지 않을 거라는 것을 의미합니까? 전혀 그렇지 않습니다.
'AI'의 'I'로 향하는 길
AI가 진정한 지성을 향해 나아가는 길에서 정복해야 할 두 가지 분야가 있습니다.
압축
LLM(Large Language Models)은 종종 '데이터 압축기'라고 말해왔는데, 이 모델들은 방대한 데이터셋(그들보다 훨씬 더 큰)을 가져와 그 지식을 가중치로 압축하는 데 뛰어납니다.
이는 부인할 수 없지만, 특히 압축의 질을 의심해볼 수 있습니다. 특히 압축을 두 단계로 나눈다면요:
- 기억( Memorization): 모델은 단어가 서로 어떻게 따르는지를 이해하지 않고 따라가는 방법을 기억합니다.
- 정규화( Regularization): 모델은 문제에 대한 간단한 해결책을 배웁니다. 모델은 단어가 서로 어떻게 따르는지를 확신할 뿐만 아니라 더 적은 가정을 토대로 그렇게 할 수 있습니다( Occam의 면도칼).
그리고 최근 기사에서 본 것처럼, 모델은 처음에 기억 한 후 정규화하는 경향이 있습니다. 다시 말해, 모델은 먼저 '만약 x이면 y'를 배우고 시간이 지남에 따라 'y가 x를 따르는 이유는 ... 를 배우게 됩니다.' 'y'가 'x'를 따르는 근본적인 인과 구조를 포착합니다.
예를 들어, 모델이 고양이가 어떻게 보이는지를 외우면 너무 구체적인 결론을 얻을 수 있습니다. 예를 들어, '털이 있는 것'이 필요한 조건이라는 결론을 내릴 수도 있습니다, 왜냐하면 보아온 고양이 대부분이 털이 있기 때문입니다.
하지만 정규화를 통해, 모델은 수염, 슬릿 모양의 눈, 꼬리와 같은 다른 특성이 고양이를 구별하는 데 더 지배적이라는 것을 깨닫습니다. 고양이의 정의를 단순화함으로써 털이 없는 고양이인 스핑크스와 같이 포함되도록 더 넓은 정의로 일반화할 수 있습니다.
요약하자면, 앨리스 이상의 예시를 기반으로 보았을 때, LLMs는 여전히 압축의 첫 번째 단계에 머물고 있는 것이 분명합니다. 그들은 기억력을 정복했을 뿐이며 (대화하는 횟수를 생각해 보면 제대로 정복한 것인지 의심스럽습니다).
하지만 그들이 언젠가 진정한 규제를 정복한다 해도, 인간 지능에 다가가기 위한 추가 단계가 있습니다.
Long-inference 모델
이 아이디어는 간단합니다: 압축이 모델들이 학습할 시간을 주는 것이라면, 장기 추론 기술은 모델들이 생각할 시간을 주는 것입니다.
간단하게 말하자면, 이러한 모델들은 '떠오르는 것에 반응하는' 것이 아닌, 수백 개, 수천 개, 또는 수백만 개의 가능한 해결책을 순회하며 최상의 해결책으로 수렴할 때까지 반복합니다.
그러나 검색이 필요한 유일한 것인지에 대해 불분명한데, LLMs가 실제 해결책으로 수렴할 것임을 나타내는 단서가 없습니다.
그래서 학계는 각 패러다임을 어떻게 해결하려고 제안하나요?
데이터 증강부터 검색까지
LLM 애호가에게 물어보면, 그들은 '검색만 있으면 된다'고 말할 것이며, 모델에게 솔루션 공간을 탐색할 수 있는 능력을 부여하는 것만으로도 AGI (인공 일반 지능 또는 신이 AGI)에 도달하는 데 충분하다고 말합니다.
Leopold Aschenbrenner과 같은 일부 연구자들은 '컴퓨트만 있으면 된다'고 주장하여 현재의 모델을 더 큰 규모로 확장하는 것만으로 충분하다고 주장합니다.
하지만 정말일까요?
개인적으로, 현재의 모델이 모든 사실을 갖고 있을 때라도 판단이 매우 부족하다는 점을 고려한다면, 이는 엄청난 일처럼 느껴집니다.
상처를 받고 더한 것 같은데 이미 백만 엑사플롭의 컴퓨팅 레벨에 도달해 있어요 (즉, 1,000,000,000,000,000,000,000,000,000 개의 연산량입니다. 정말 많죠).
이제 엘엘엠이 '이상한 나라의 앨리스'와 같은 간단한 추론 문제를 해결할 수 있도록 하려면 얼마나 많은 제로가 더 필요할까요?
다행히 대부분의 연구자들은 덜 순진하고 여러 가지 방법을 제안하고 있어요:
- 데이터 증강. 모델이 더 나은 추론을 하려면 더 나은 추론 데이터를 보아야 해요. 그래서 인공지능 연구소들은 모델이 문제를 더 나은 추론 단계로 분해하는 데 도움이 되는 합성 데이터셋을 구축하는 데 상당한 투자를 하고 있어요. 예를 들어, OpenAI의 PRM800k 데이터셋이 있어요. 이 방법의 최근 성공 사례 중 하나는, 최근에 Cosine이 발표한 매우 인상적인 Genie 에이전트예요.
- 훈련을 과도하게 확장: 진정한 압축은 모델이 추론 회로를 규제하고, 추론 과정을 기억하지 않고 내재화할 때 옵니다. 최근 인기를 끌고 있는 한 가지 방법은, 교육을 과도하게 확장하는 것인데요. 이렇게 하면 모델이 문제에 대한 더 간단한 해결책을 찾을 시간을 제공하죠.
- 테스트 시간 계산: 긴 추론 모델 부분에서 언급된 것처럼, 모델들이 답하기 전에 솔루션을 찾을 수 있게 해요. 중요한 점은 두 가지 가능한 솔루션 중 어느 것을 선택할지 결정할 방법이 필요하다는 거예요. 구글과 같은 기업들은 알고리즘 비교 방법(두 응답의 엔트로피를 측정하고, 더 낮은 응답인 더 간단한 해결책을 유지)을 시험해 보았지만, 가장 인기 있는 방법은 검증자(verifiers)를 사용하여, 생성자의 솔루션을 비평하고 솔루션 공간을 탐색할 수 있도록 돕는 추가 모델들 사용하는 것입니다 (이것은 아주 복잡한 문제입니다).
모두 보아하니, 대부분의 새로운 모델은 이러한 범주 중 하나 이상에 속하며 곧 추론 능력이 증가할 것으로 예상됩니다.
그러나 한 가지 마지막 포인트가 있습니다:
이 세 가지 방법만으로 모델이 학습 데이터를 극복하는 데 충분합니까? 이러한 방법만으로 모델이 혁신하거나 이전에 본 적이 없는 새로운 해결책을 만들 수 있게 충분합니까?
아닙니다. 그것을 위해 느끼는 것은 두 가지 부분이 여전히 부족한 것 같습니다:
- 깊이(Depth): 안드레이 카르파티가 최근 트윗에서 강렬히 언급한 대로, 아직 LLM을 깊게 훈련시키는 방법을 찾지 못했습니다. 이로 인해 LLM은 어떤 작업에서도 초인적인 수준에 이르지 못하고 있습니다. 주요 문제는 알파제로와 같은 모델과 달리, 열린 문제에서 초인적 능력을 달성하는 것은 그들의 행동의 품질을 측정하고 그 피드백으로부터 학습하는 직접적인 방법이 결여되어 있기 때문에 더 어렵다는 것입니다. 오늘날의 LLM은 여러 가지 일에 능숙하지만 어느 것 하나에 뛰어나지 못합니다.
- 능동 추론(Active inference): 현재 최고의 모델들은 훈련 중에만 배우기 때문에 점점 변화하는 현실 세계에 대비하기에 완전히 무장하지 못합니다. 그러므로 우리는 그들이 세상을 예측하면서 배울 수 있는 메커니즘을 찾아야 합니다.
바로 문제점을 짚자
어떤 방식으로든, 한 가지는 분명합니다: 아직 성장할 여지가 많으며, 현재 인공지능의 능력은 지나치게 과장되어 있습니다.
그러나 기업 수준에서 특히 인공지능의 부정적인 채용은 회사와 고객 모두가 이러한 모델을 어떻게 사용해야 하는지 미숙한 인식 때문이 대부분입니다.
하지만 그것은 사회의 잘못이 아니에요. 대형 기술 기업과 그들의 자회사 인공지능 연구소들이 실현되지 않는 많은 약속과 아이디어를 판매하고 있죠.
가짜 없는 이야기로 진행해 봅시다.