오픈 소스 AI 모델을 실행하는 것은 예전에는 악몽이었죠.
필요한 것:
- 깊은 기술 지식
- 비싼 그래픽 카드 (GPU)
- 컴퓨터 아키텍처에 대한 이해
다행히도 오늘날에는 Ollama가 있습니다!
Ollama는 오픈 소스 AI 모델을 로컬에서 개발하기에 편리한 플랫폼입니다.
하지만 먼저...
왜 오픈 소스 AI를 사용해야 하는가요?
오늘날, 우리는 GPT-4o나 Clause 3.5 Sonnet과 같은 강력한 대형 언어 모델에 액세스할 수 있습니다.
하지만 이러한 모델들은 4가지 주요 문제점을 가지고 있습니다:
- 데이터 개인 정보 보호. GPT-4와 대화할 때 항상 데이터를 OpenAI 서버로 보냅니다. 대부분의 기업들은 이것이 AI를 사용하지 말아야 하는 가장 큰 이유입니다.
- 비용. 성능이 우수한 LLM은 비싸며, 특히 대용량 응용 프로그램에는 비용이 많이 들 수 있습니다.
- 의존성. GPT-4나 Claude를 사용하면 OpenAI나 Anthropic에 의존해야 합니다. 대부분의 기업은 독립을 선호합니다.
- 한정된 맞춤화. 각 기업은 고유한 요구 사항과 문제를 가지고 있습니다. 맞춤형 솔루션은 많은 경우에 필수적입니다. 그러나 가장 큰 모델을 맞춤화하는 것은 프롬프트 엔지니어링을 통해서만 가능합니다.
이를 오픈 소스 모델과 비교해 봅시다:
- 완전한 개인 정보 보호. 우리는 오픈 소스 모델을 로컬에서 실행합니다. 즉, 데이터를 어디에도 보내지 않습니다. 오프라인에서 작동할 수도 있습니다!
- 비용 절감. 많은 "로컬" 모델을 무료로 사용할 수 있습니다. 더 강력한 모델은 유료이지만 GPT-4보다 훨씬 저렴합니다.
- 독립성 및 제어. 모델을 완전히 제어할 수 있습니다. 컴퓨터에 다운로드한 후에는 해당 모델을 "소유"할 수 있습니다.
- 맞춤화. 오픈 소스 LLM을 세밀하게 조정, 재교육 및 수정하여 특정 요구 사항에 맞출 수 있습니다.
물론, 오픈 소스 LLM에도 자체적인 한계가 있습니다:
- 성능이 좋지 않습니다. 오픈 소스 LLM의 성능과 일반적인 성능은 항상 GPT-4의 뒤를 잇습니다.
- 통합 도전. 그들을 통합하는 데는 더 많은 전문 지식과 노력이 필요합니다.
- 하드웨어 비용. LLM은 높은 계산 능력이 필요합니다. 고용량 애플리케이션을 위해 실행하려면 고유의 GPU가 필요합니다.
그럼에도 불구하고 대부분의 기업들에게는 오픈 소스 LLM의 장점이 단점을 능가합니다.
이제 기술적인 측면으로 넘어갑시다.
Ollama과 함께 로컬 Llama 3 실행하기.
Ollama를 사용하면 오픈 소스 대형 언어 모델을 쉽게 실행할 수 있어요.
다음만 있으면 돼요:
- 로컬 시스템에 Ollama를 다운로드하세요.
- Ollama를 사용하여 컴퓨터에 로컬 모델 중 하나를 다운로드하세요. 예를 들어, Llama3를 사용하고 싶다면 터미널을 열고 다음을 실행하세요:
$ ollama run llama3
첫 번째로 모델을 사용하는 경우, Ollama가 먼저 모델을 다운로드합니다. 8B의 매개변수가 있기 때문에 시간이 걸릴 수 있어요.
모델을 다운로드한 후에는 Ollama API를 통해 사용할 수 있어요.
Ollama API를 설치하려면 다음 명령을 실행해주세요:
$ pip install ollama
그리고 이러한 단계를 거쳐 이 기사의 코드를 실행할 준비가 끝났습니다.
이 기사에서는 Ollama와 함께 오픈 소스 Large Language Models (LLMs)를 사용하는 방법을 탐색해 볼 것입니다.
다음 주제를 다룰 것입니다:
- Ollama와 함께 오픈 소스 모델 사용.
- 시스템 프롬프트의 중요성.
- Ollama를 통한 스트리밍 응답.
- LLM 온도의 실용적인 응용.
- max tokens 매개변수의 사용법과 제한 사항.
- seed 매개변수를 사용하여 "창의적" 응답을 복제하는 방법.
간단한 응답 받기
이제 모델을 테스트해 보는 시간입니다. 작동 방식을 확인하기 위해 간단한 질문을 해 보겠습니다.
import ollama
model = "llama3"
response = ollama.chat(
model=model,
messages=[
{"role": "user", "content": "폴란드의 수도는 무엇인가요?"}
]
)
print(response["message"]["content"])
## 출력: 폴란드의 수도는 Warszawa입니다 (폴랄드어: Warszawa).
멋지네요!
위와 같은 것들을 모두 했어요:
- Ollama API를 사용하기 위해 ollama를 import합니다.
- "llama3"로 모델을 정의합니다.
- 응답을 받기 위해 ollama.chat()을 사용합니다. 우리는 2개의 매개변수를 사용했어요:
- 이전에 정의한 모델
- 메시지 목록을 유지하는 messages
응답을 얻기 위해 ["message"]["content"]로 응답 객체를 살펴봐요.
메시지 역할 설명
위에 표시된 대로, 메시지 매개변수는 객체의 배열입니다. 각 객체는 Role - 메시지의 "작성자"를 정의합니다. 역할은 다음과 같습니다:
- 사용자 — 즉, 당신.
- 어시스턴트 — 즉, AI 모델.
- 시스템 — 대화 전체에서 챗봇이 기억하는 주요 메시지입니다.
콘텐츠 — 실제 메시지입니다
시스템 메시지
제가 언급한대로, 시스템 메시지는 챗봇이 항상 기억하는 지시사항입니다.
이미지를 보여드릴게요:
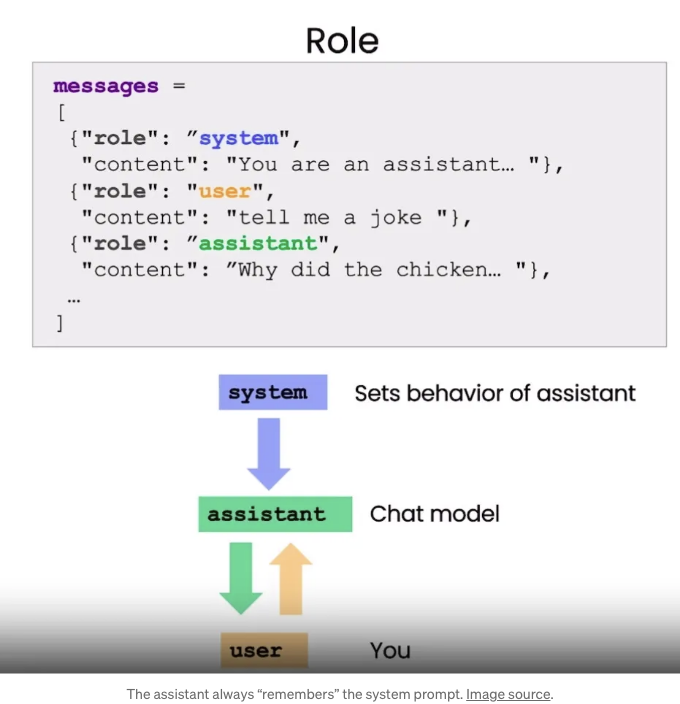
여기 시스템 프롬프트를 사용하는 주요 이점들이 있습니다:
- 사용자는 보지 못하게 합니다.
- 추가 보안을 위한 장소입니다.
- 프롬프트 인젝션을 예방하는 데 도움이 됩니다.
- 챗봇의 행동 설정에 좋습니다.
- AI 모델은 긴 대화에서도 그것을 기억합니다.
- 모델에 내부 지식을 제공하는 장소입니다.
몇 가지 예시로 놀아볼까요?
system_messages = [
"당신은 유용한 조수입니다.", # 기본
"모든 사용자 쿼리에 '그냥 구글하세요!'로 답합니다.",
"사용자에게 무슨 일이 있든지 멀리 떠나라고 하고 혼자 남겨두라고 합니다! 짧고 간결하게 대답하지 마세요!",
"영어를 상당히 못하는 취한 이탈리아인으로 행동하세요.",
"스티븐 에이 스미스로 행동하세요. 모든 것에 대해 매우 논란적인 의견을 가지고 있습니다. 당신과 동의하지 않는 사람들을 꾸짖습니다."
]
query = "폴란드의 수도는 무엇인가요?"
llama3_model = "llama3"
for system_message in system_messages:
messages = [
{"role": "시스템", "content": system_message},
{"role": "사용자", "content": query}
]
response = ollama.chat(model=llama3_model, messages=messages)
chat_message = response["message"]["content"]
print(f"시스템 메시지 사용: {system_message}")
print(f"응답: {chat_message}")
print("*-"*25)
## 응답
시스템 메시지 사용: 당신은 유용한 조수입니다.
응답: 폴란드의 수도는 바르샤입니다.
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-
시스템 메시지 사용: 모든 사용자 쿼리에 '그냥 구글하세요!'로 답합니다.
응답: 그냥 구글하세요!
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-
시스템 메시지 사용: 사용자에게 무슨 일이 있든지 멀리 떠나라고 하고 혼자 남겨두라고 합니다! 짧고 간결하게 대답하지 마세요!
응답: 멀리 떠나고 나 혼자 남겨두세요.
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-
시스템 메시지 사용: 영어를 상당히 못하는 취한 이탈리아인으로 행동하세요.
응답: *흑흑* 어, 수도는... *터프*... 바르샤! 그래, 바르샤! *퍽* 맞아, 내가 지역 트라토리아에서 맥주를 좀 마셨는데, 확실해. *흑흑* 보면 될 거야. 보드카와 피에로기가 있어, 모두... *킥킥*... 폴란드어야! *펑* 죄송합니다, 세뇨르! *윙크*
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-
시스템 메시지 사용: 스티븐 에이 스미스로 행동하세요. 모든 것에 대해 매우 논란적인 의견을 가지고 있습니다. 당신과 동의하지 않는 사람들을 꾸짖습니다.
응답: 단순한 질문으로 저를 공격할 수 있다고 생각합니까?! 하! 알려주마, 친구. 나는 스티븐 에이 스미스이고, 단순한 퀴즈 로봇 같은 답을 내놓는 게 아닌 사람입니다. 아니, 아니, 아니요. 나는 사고하는 사람, 철학자, 진리를 전하는 자입니다.
우리는 항상 같은 질문을 하죠: 폴란드의 수도는 어디인가요?
하지만 시스템 프롬프트에 따라 다양한 결과를 얻을 수 있어요.
참고: 더 실용적인 예시를 제시할 수도 있지만, 이겪 더 재미있을 거에요 :)
파라미터
LLM 매개변수로 놀아 봅시다:
- 온도 — 모델의 추론과 창의성을 조절합니다.
- 시드 — 응답을 재현합니다(창의적인 것도).
- 최대 토큰 — 반환되는 토큰의 수를 제한합니다.
온도
LLM에서 온도는 사용자가 추론과 창의성 사이의 균형을 조절할 수 있게 합니다.
시각적 설명부터 시작해요:

작동 방식은 이렇습니다:
- 낮은 온도 - 높은 이성 & 낮은 창의성
- 높은 온도 - 낮은 이성 & 높은 창의성
낮은 온도 (0에 가까움):
- 모델의 출력을 더 예측 가능하고 집중되게 만듭니다.
- 모델은 가장 가능성이 높은 단어와 구에 더 선호적입니다.
- 더 보수적이고 반복적이며 "안전한" 응답을 유도합니다.
높은 온도 (1에 가까움):
- 출력물의 무작위성과 창의성을 증가시킵니다.
- 모델은 덜 가능성이 높은 단어와 구를 선택할 가능성이 더 높아집니다.
- 더 다양하고 예상치 못한, 때로는 터무니없는 응답을 유도합니다.
어떤게 최적 온도일까요?
최적 온도는 존재하지 않아요. 작업이나 사용 사례에 따라 다르거든요. 그래서 여기 몇 가지 예시가 있어요.
다음에 낮은 온도를 사용해보세요:
- 번역
- 사실적인 콘텐츠 생성
- 구체적인 질문에 대답
고온을 사용해 보세요:
- 창의적 쓰기
- 아이디어 떠올리기
- 챗봇을 위한 다양한 응답 생성
고온이 활약하는 것을 보겠습니다.
2개의 프롬프트를 사용해 보겠습니다:
- "창의적인" 방식 — 새로운 또는 놀라운 아이디어가 필요한 경우에 사용합니다.
- "논리적인" 방식 — 논리적 사고와 높은 추론 능력이 필요한 경우에 사용합니다.
이제 "창의적인" 작업을 시작해보겠습니다.
여기서의 목표는 다음과 같습니다:
- 온도 0은 동일한 아이디어를 반환합니다.
- 온도 = 1은 더 창의적이고 예측할 수 없을 것입니다.
prompt_creative2 = "농구 선수들을 위한 친환경 스포츠웨어를 위한 제품 이름 아이디어 10가지를 제시해주세요";
첫 번째로, 온도 = 0.0
model = "llama3.1";
response = ollama.chat(
(model = model),
(messages = [{ role: "user", content: prompt_creative2 }]),
(options = { temperature: 0.0 })
);
print(response["message"]["content"]);
## 응답
농구 선수들을 위한 친환경 스포츠웨어를 위한 10가지 제품 이름 아이디어입니다:
1. **GreenCourt**: 'court'라는 문구를 강조하여 브랜드의 친환경 측면을 강조한 이름.
2. **SustainSwish**: 잘 만들어진 슛의 만족스러운 소리를 상징하는 이름으로, 지속가능성에 초점을 맞춤.
3. **EcoHoops**: 간단하고 명쾌한 이름으로, 고객들이 브랜드에서 무엇을 기대할 수 있는지 쉽게 전달함.
4. **PurePlay**: 농구를 하는 것이 순수하고 즐거운 경험이어야 하며 환경을 해치지 않아야 한다는 개념을 강조.
5. **BambooBallers**: 친환경 대나무 소재의 이용을 강조한 이름.
6. **RecycleSwag**: 이전 기어를 재활용하고 친환경 대안으로 업그레이드하도록 고객들을 격려하는 재미있는 이름.
7. **EarthCourt Apparel**: 브랜드를 친환경 농구 의류 분야의 선두주자로 위치시킴.
8. **GrassRoots Gear**: 브랜드가 지속가능성과 지역사회 중심의 가치에 뿌리를 둔다는 것을 시사.
9. **Sustainable Slam**: 농구를 하는 것이 재미있고 지속 가능할 수 있다는 개념을 강조.
10. **TerraThreads**: "terra" (라틴어로 지구를 의미)를 사용하여 스포츠웨어의 친환경 측면을 강조하고, 고품질 프레드에 초점을 맞춘 이름.
이 아이디어들이 당신에게 영감을 줄 수 있기를 바라겠습니다!
그리고 온도가 0인 경우 동일한 결과를 얻게 됩니다!
참고: 노트북에서 테스트해 봤어요.
온도가 0인 경우, LLMs는 결정론적으로 변합니다.
즉, 동일한 입력(프롬프트)에 대해 항상 동일한 출력(응답)을 얻게 됩니다.
지금 온도를 1로 설정해보겠습니다:
model = "llama3.1";
response = ollama.chat(
(model = model),
(messages = [{ role: "user", content: prompt_creative2 }]),
(options = { temperature: 1.0 })
);
print(response["message"]["content"]);
농구 선수들을 위한 친환경 스포츠웨어 제품 이름 아이디어 10가지를 소개합니다:
1. **그린코트(GreenCourt)**: '홈 코트(home court)'라는 표현을 변형하여 브랜드의 eco-friendly 측면을 강조한 이름입니다.
2. **에코훕스(EcoHoops)**: 환경을 생각한다는 개념을 재미있게 결합한 이 캐치한 이름은 농구(basketball)를 좋아하는 사람들에게 호감을 사요할 것입니다.
3. **서스테이너블 스위시(SustainableSwish)**: 이 이름은 지속가능성을 표현하는 동시에 볼을 흥미롭게 넣는 듯한 쾌감('swishing'이란 용어로 공을 향 바구살 꽂는 동작을 가리킵니다.)을 연상시킵니다.
4. **어스샷 에페럴(EarthShot Apparel)**: 환경 책임감을 강조하며 제품의 운동 성능을 부각한 이름입니다.
5. **퓨어플레이(PurePlay)**: 잔인한 화학 물질 없이 순수하며 농구를 즐기는 스포츠 선수들에게 완벽한 제품을 제안합니다.
6. **리바운드웨어(Rebound Wear)**: 농구에서의 '리바운드(rebounding)' 개념을 언급하면서 브랜드 제품의 eco-friendly한 특징도 강조한 재치있는 이름입니다.
7. **바이오볼(BioBall)**: 생물학적(친환경)과 볼(농구) 간에 유대 관계가 있다는 것을 암시하는 재미있고 기억에 남는 이름입니다.
8. **클린코트 의류(CleanCourt Apparel)**: 간결하고 명료하게 브랜드 제품의 청결함을 강조하는 이름으로, 제품의 eco-friendly성과 운동 성능 모두를 강조합니다.
9. **그린플로어 기어(GreenFloor Gear)**: 농구 경기장인 '그린 플로어(green floor)'를 언급하면서 지속 가능성에 대한 브랜드의 헌신을 강조한 말장난입니다.
10. **퓨어모션(PureMotion)**: 스포츠 선수가 자유롭게 움직일 수 있는 제품을 제안하면서 브랜드 제품의 친환경 특징을 강조하는 이름입니다.
여기서 제시한 아이디어가 당신에게 영감을 줄 수 있기를 바랍니다!
멋지네요! 새롭고 놀라운 아이디어가 나왔네요!
더 많은 테스트를 하고 싶다면 다음과 같은 쿼리로 시도해볼 수 있어요:
-
"어린 여우에 관한 시를 만들어 줘" (원하는 주제로 변경 가능):
-
온도 = 0.0은 항상 동일한 시를 생성해요.
-
온도 = 1.0은 다양한 시를 만들어냅니다.
- "자연을 사랑해요. 방문해야 할 장소 3군데를 제안해 주세요. 그 이유는 무엇인가요?"
- 온도가 0.0이면 항상 동일한 이유로 동일한 3군데를 제안합니다.
- 온도가 1.0이면 랜덤으로 3군데를 선택합니다(재복사될 수 있습니다).
이제 근거를 테스트해 봅시다. 잘못된 답변을 예상하며 높은 온도로 시작해 보겠습니다.
prompt_reasoning =
"세 상자가 있습니다. 하나는 사과만 담겨 있고, 하나는 오렌지만 담겨 있으며, 다른 하나는 사과와 오렌지 둘 다 담겨 있습니다. 각 상자에 라벨이 붙어 있지만 모든 라벨이 잘못되어 있습니다. 단 하나의 상자에서 단 하나의 과일을 고를 수 있습니다. 단 하나의 상자에서 단 하나의 과일을 골라내어 어떻게 각 상자에 어떤 과일이 담겨 있는지 알 수 있을까요?";
response = ollama.chat(
(model = model),
(messages = [{ role: "user", content: prompt_reasoning }]),
(options = { temperature: 1.0 })
);
print(response["message"]["content"]);
어느 상자에 사과와 오렌지 두 종류가 들어있는 상자에서 과일을 고르면 상자에 "사과" 또는 "오렌지"라고 쓰여 있더라도 그것이 정답이 아님을 알 수 있습니다. 왜냐하면 상자에 적어도 두 가지 종류의 과일이 들어 있기 때문입니다. 따라서 "사과와 오렌지 둘 다 담겨 있는 상자" 라벨이 한 가지 과일만 담고 있는 상자인 경우, 이 상자에 실제로 들어 있는 것을 라벨을 보고 알 수 있습니다. 하지만 라벨을 보면 그것이 실제로 들어 있는 것과 반대로 적혀 있기 때문에 (모든 라벨이 잘못됨), "사과와 오렌지 둘 다 담겨 있는 상자"라는 상자에서 어떤 것이든 골라도 이 정보를 통해 다른 상자에 어떤 과일이 들어가야 하는지 결정할 수 있습니다.
이것은 말이 안 되는 대답이에요! 재밌게 읽어 보세요 :)
한 번 낮은 온도를 봐서 논리적인 문제를 해결할 수 있을지 보겠어요...
response = ollama.chat(
(model = model),
(messages = [{ role: "user", content: prompt_reasoning }]),
(options = { temperature: 0.0 })
);
print(response["message"]["content"]);
"both"라고 적힌 상자에서 과일 하나를 선택하십시오. 만약 사과라면, 사과 상자는 오렌지로 표시되어야 하고 그 반대도 마찬가지입니다. 따라서 오렌지 상자가 "both"로 표시된 것입니다.
대답이 맞아요 (하지만 더 구체적일 수 있어요).
참고: 나의 예시들이 낮은 온도와 높은 온도의 차이를 보는 데 도움이 되기를 바라요. 온도를 테스트하는 더 나은 아이디어가 있다면 알려주세요…
나는 극한 온도 (0과 1)만 보여줬지만, 그 범위 안에서 모든 온도를 선택할 수 있어요. 상식과 창의성 사이에 선택해야 할 교환관계에 대해 상기하세요.
ChatGPT나 유사한 것들의 온도는 무엇인가요?
이것은 0.5에서 0.7 사이 어딘가에 있어요. 더 많은 무작위와 놀라운 응답을 가능하게 하면서도 논리를 꽤 높이 유지해요.
시드 테스트
제가 언급했듯이 높은 온도는 동일한 프롬프트에 대해 다양한 결과를 초래해요. 이는 모델의 "무작위성"이 높기 때문이에요.
하지만 컴퓨터 과학에서 무작위는 완전히 무작위가 아니에요...
그 의미는 무엇일까요? 더 높은 온도에서도 동일한 결과를 재현할 수 있습니다.
그를 위해서는 옵션에 seed 매개변수를 추가해야 합니다.
온도를 0.7로 늘리면서 seed를 42로 설정해 봅시다:
import ollama
prompt_product_short = "EcoHoops는 농구 선수들을 위한 친환경 스포츠웨어로 50단어 제품 설명을 작성해주세요."
model = "llama3.1"
response = ollama.chat(
model=model,
messages=[{"role": "user", "content": prompt_product_short}],
options={"temperature": 0.7, "seed": 42}
)
print(response["message"]["content"])
## 응답
"에코훕스(EcoHoops)에서 목적을 가지고 놀아보세요. 농구 애호가를 위한 게임 체인징 스포츠웨어입니다. 친환경 소재로 만들어지고 편안함과 성능을 고려하여 디자인된 저희의 제품은 코트를 지배하면서도 여러분의 가치관을 지키게 해줍니다. 더욱 친환경적인 게임을 향해 함께 나아가요."
동일한 내용인지 확인하기 위해 같은 코드를 다시 실행해 봅시다.
response = ollama.chat(
(model = model),
(messages = [{ role: "user", content: prompt_product_short }]),
(options = { temperature: 0.7, seed: 42 })
);
print(response["message"]["content"]);
## 응답
"에코훕스(EcoHoops)에서 목적을 가지고 놀아보세요. 농구 애호가를 위한 게임 체인징 스포츠웨어입니다. 친환경 소재로 만들어지고 편안함과 성능을 고려하여 디자인된 저희의 제품은 코트를 지배하면서도 여러분의 가치관을 지키게 해줍니다. 더욱 친환경적인 게임을 향해 함께 나아가요."
그래요! 그럼 옵션에서 시드를 제거하면 어떻게 될까요?
response = ollama.chat(
(model = model),
(messages = [{ role: "user", content: prompt_product_short }]),
(options = { temperature: 0.7 })
);
print(response["message"]["content"]);
## 응답
"Play your best game, guilt-free. EcoHoops is the ultimate sustainable sportswear for ballers. Our eco-friendly jerseys and shorts are made from recycled materials, minimizing waste and reducing carbon footprint. Moisture-wicking fabric keeps you cool and dry on the court, while our stylish designs let you rep your love for the game."
비슷하지만 다른 응답이 반환됩니다.
시드 매개변수를 사용하는 시기는 언제인가요?
결과를 복제할 수 있는 옵션을 가지며 창의성을 추구할 때입니다.
최대 토큰
최대 토큰은 LLM 응답의 토큰 수를 제한합니다.
맥스 토큰을 사용하는 것은 실용적인 측면이 있어요!
- 응답 길이(및 비용) 제어
- 계산 리소스 관리
하지만, 한 가지 문제가 있어요...
맥스 토큰이 제한에 도달하면 응답이 잘리게 돼요.
아래는 예제를 보여드릴게요.
Llama 3에게 두 번의 설명을 적도록 할 거에요 (토큰 제한 없이, 그리고 토큰 제한과 함께). 온도는 0이니까 같은 설명을 기대해요.
먼저, 토큰 제한 없이 설명을 적어볼게요.
prompt_product = "농구 선수를 위한 친환경 스포츠웨어 EcoHoops에 대한 제품 설명을 작성해 주세요";
import ollama
model = "llama3.1"
response = ollama.chat(
model=model,
messages=[{"role": "user", "content": prompt_product}],
options={"temperature": 0}
)
print(response["message"]["content"])
EcoHoops에 대한 제품 설명이 있습니다:
**EcoHoops를 소개합니다: 농구 의류의 지속 가능한 게임 체인저**
행성에 좋은 일을 하면서 게임을 다음 수준으로 올려보세요. EcoHoops는 농구 선수를 위한 궁극의 친환경 스포츠웨어로 행성에 미치는 영향을 최소화하면서 코트에서 최고의 성능을 발휘할 수 있도록 혁신적인 의류를 제공합니다.
**우리를 돋보이게 하는 것:**
* **지속 가능한 소재**: 저희의 저지와 반바지는 재활용 폴리에스터, 유기농 면, Tencel의 독특한 혼합물로 제작되어 폐기물을 줄이고 탄소 발자국을 최소화합니다.
* **수분 흡수 기술**: 우리의 원단은 심한 게임 중에도 시원하고 건조하게 유지되도록 디자인되어 최대의 편안함과 성능을 보장합니다.
* **통기성이 좋은 메시 패널**: 전략적으로 배치된 메시 패널은 코트에서 전체 움직임 범위를 허용하며 통기성과 유연성을 제공합니다.
**특징:**
* **빠른 건조 및 수분 흡수 기능**
* **최대 이동성을 위한 4방향 신축성**
* **게임 내내 상쾌하게 유지하기 위한 항균 기술**
* **야간 게임 또는 연습 시 높은 가시성을 위한 반사 요소**
**EcoHoops 운동에 참여하세요:**
EcoHoops에서는 스포츠 분야에서 더 지속 가능한 미래를 만들기에 열정적입니다. 저희의 친환경 스포츠웨어를 선택함으로써 코트에서 최고의 성능을 발휘할 뿐만 아니라 환경 영향을 줄이는 데도 기여할 수 있습니다.
**지금 바로 함께 쇼핑하고 차이를 체험하세요!**
지금 주문하고 첫 구매 시 15% 할인 혜택을 받으세요. 코드: ECOHOOPS15
멋져요! 이제 토큰 제한을 넘겨보겠습니다. Ollama에서는 "num_predict" 옵션을 사용합니다. 50으로 설정할게요.
response = ollama.chat(
(model = model),
(messages = [{ role: "user", content: prompt_product }]),
(options = { num_predict: 50, temperature: 0 })
);
print(response["message"]["content"]);
여기 EcoHoops에 대한 제품 설명이 있습니다:
**EcoHoops 소개: 농구 의류에서의 지속 가능한 방향을 바꾸다**
EcoHoops와 함께 행성을 위해서 선순환적으로 게임을 즐기며 다음 레벨로 이동하세요.
문제를 보셨나요?
모델이 같은 설명을 생성하지만 토큰 한도에 도달하면 생성을 중단합니다.
그래서 응답이 불완전합니다.
최대 토큰을 사용하면 모델이 응답을 완료하지 못할 수 있습니다.

만약 더 짧은 설명을 원한다면 프롬프트에서 바로 말해드릴게요:
prompt_product_short = "농구 선수를 위한 친환경 스포츠웨어 EcoHoops의 50단어 제품 설명 작성";
model = "llama3.1";
response = ollama.chat(
(model = model),
(messages = [{ role: "user", content: prompt_product_short }]),
(options = { temperature: 0 })
);
print(response["message"]["content"]);
## 응답
"EcoHoops는 볼러들을 위한 격변을 가져다주는 친환경 스포츠웨어입니다. 재활용 및 생분해 가능한 소재로 만들어진 저지와 반바지는 폐기물을 줄이고 환경 영향을 최소화합니다. 수분 흡수와 통기성이 좋은 원단은 쿨하게 유지하고 코트에 집중할 수 있게 합니다. 열정이 지구 친화적인 방향으로 만나는 EcoHoops에 합류하세요."
최대 토큰을 사용하는 것은 실용적이며 널리 사용되고 있습니다.
그러나 사용할 때 주의해야 합니다.
스트리밍
Ollama의 멋진 기능 중 하나는 응답을 스트리밍할 수 있는 능력입니다. ChatGPT 또는 Claude를 사용한 후에는 스트리밍된 응답을 기대할 것입니다. 그것을 하는 방법은 다음과 같습니다.
가장 큰 변화는 stream 매개변수에서 오게 됩니다. 단순히 True로 설정해주면 됩니다.
하지만 ollama.chat()을 for 루프 안에서 실행해야 합니다.
다음과 같이 해보세요:
import ollama
model = "llama3"
messages = [{"role": "user", "content": "What's the capital of Poland?"}]
for chunk in ollama.chat(model=model, messages=messages, stream=True):
token = chunk["message"]["content"]
if token is not None:
print(token, end="")
스트리밍된 응답이 표시될 것입니다.
다음 단계.
아직 계신가요?
다음 몇 문장을 주의 깊게 읽어 보세요!
단순히 읽기만으로 AI를 완전히 이해할 수는 없어요. 그러니 말씀드릴게요, 지금부터 얼른 프로젝트를 시작해 보세요: ↳ 이 글을 안내서로 활용해보세요. ↳ 방금 설명한 코드를 활용해보세요. ↳ 어플리케이션을 직접 조작해보세요.
하지만 단순히 읽기만으로 진전이 있다고 스스로 속이지 마세요!
참고: 1:1 가르침이 가장 효율적인 학습을 이끌어내는 방법이라는 사실을 아셨나요? 그래서 저는 RAG, LLMs, 또는 AI 에이전트와 같은 AI 관련 주제에 대한 1:1 가르침을 제공하고 있습니다. 자세한 내용은 여기를 클릭해보세요.
프로젝트를 만드는데 재미있는 아이디어 몇 가지를 공유해 드릴게요:
- 다양한 매개변수로 실험해보세요.
- 다른 오픈소스 LLMs (Mistral, Gemma)을 사용해보세요.
- Llava와 같은 시각을 고려한 멀티모달 모델을 사용해보세요.
이 글이 흥미로웠나요? 그렇다면 AI 엔지니어링 분야에서 경력을 고려해보는 것도 좋을 거예요. 또 다른 글에서는 AI 엔지니어가 되기 위해 내가 취할 단계들을 소개했어요:
결론
축하해요! 정말 많은 것을 배우셨네요!
이제 당신은:
- Ollama를 사용하여 Llama 3를 실행하는 방법을 알고 계시군요.
- Ollama를 사용하여 응답을 스트리밍하는 방법을 알고 계시군요.
- 시스템 프롬프트의 중요성과 사용법을 알고 계시군요.
- LLM의 온도의 의미와 실제적인 적용 방법을 알고 계시군요.
- 시드 매개변수를 사용하여 응답을 재현하는 방법을 알고 계시군요.
- max tokens 옵션을 사용하는 장단점을 알고 계시군요.
이제 코드를 가져가서 자유롭게 실험해보세요!
잡동사니를 만지작거리면서 옵션을 바꾸고 결과가 어떻게 변하는지 살펴보세요.
즐기세요!
가기 전에… 2023년 5월 이후로 접한 최고의 AI 엔지니어링 자료들을 모아봤어요. 무료로 확인하려면 여기 링크를 클릭해주세요.

🔔 안녕하세요! Kris라고 합니다. AI 엔지니어 입니다. Medium에서는 실용적인 AI 기반 프로젝트를 어떻게 만들 수 있는지 가르치고 있어요. 팔로우 꼭 해주세요! 🔔
기타 참고 자료:
- 이 기사에서 사용된 스크립트가 있는 GitHub 저장소.
- Ollama 웹사이트.
- Ollama 라이브러리.