🐍 이미지, 비디오 및 시계열을 위한 맘바 상태 공간 모델로 향하면서
맘바만으로 충분할까요? 분명히, 2017년 A. Vaswani 등이 소개한 'Attention is all you need'를 통해 소개된 Transformer 아키텍처에 대해 많은 사람들이 오랫동안 그렇게 생각해 왔습니다. 그리고 의심의 여지없이, Transformer는 딥 러닝 분야를 한 번 더 혁신시켰습니다. 그 일반적인 아키텍처는 텍스트, 이미지, 비디오 및 시계열과 같은 다양한 데이터 형식에 쉽게 적응할 수 있습니다. 그리고 Transformer에 계산 리소스와 데이터를 투입할수록 더 성능이 향상되는 것으로 보입니다.
그러나 Transformer의 어텐션 메커니즘에는 중대한 단점이 있습니다: O(N²) 복잡성을 가지고 있어 시퀀스 길이에 제곱적으로 증가합니다. 즉, 입력 시퀀스가 클수록 더 많은 계산 리소스가 필요하며, 이로 인해 대규모 시퀀스는 종종 처리하기 어려울 수 있습니다.
❓ 그 질문은: 더 나은 방법이 있을까요? 성능을 유지하면서 O(N²) 복잡성을 줄일 수 있는 방법이 있을까요? 그럼 이 새로운 아키텍처는 어떻게 보일까요?
🏊♂️ 함께 뛰어들어서 함께해요! 여기 Mamba 상태 공간 모델의 다단원 집중 공략 시리즈로, 왜 Mamba가 많은 애플리케이션과 데이터 형태에 대해 흥미로운 새로운 일반 목적 방법론인지 발견할 것입니다.
개요
- 이 시리즈는 무엇에 대해인가요?
- 새로운 모델이 필요한 이유는 무엇인가요?
- 구조화된 상태 공간 모델
- 여기 Mamba가 나타납니다
- 비전 Mamba — 이미지에 적용된 Mamba
- 비디오Mamba — 비디오 이해
- MambaMixer — 채널에 선택성 추가
- Mamba-2 — 주의와 SSMs 간 간극을 메우다
- 결론
- 추가 읽을거리 및 자료
1. 이 시리즈는 무엇에 대해인가요?
당연히 Mamba에 관한 모든 것인데요, 강력한 Transformer를 대체할 모델이라고 말할 수 있어요! 하지만 이게 어떻게 작동하는 걸까요? 논문에 언급되지 않은 세부 사항은 무엇인가요? 그리고 어떻게 모든 종류의 데이터 모달리티를 처리할까요? 이런 질문들과 더 많은 질문에 답변을 찾을 수 있는 시리즈 기사가 있습니다.
특히, 1부에서는 RNN과 Transformer의 장단점을 이해하고 Mamba의 탄생을 도와 주는 새로운 아키텍처가 필요하다는 동기부여를 검토할 것입니다. 더불어 해당 시리즈의 모든 부분에 대한 기본 개념을 소개하며 Mamba의 성공을 바탕으로 한 많은 최근 연구 논문을 소개할 것입니다.
2부에서는 Mamba의 기반이 된 구조화된 상태 공간 모델(SSMs)을 살펴볼 것입니다. N² 복잡도 문제 해결하는 반면, 장거리 의존성 처리 및 성능 향상에 대한 다른 장애가 발생한다는 것을 발견할 것입니다. 3부에서는 Mamba를 소개하고, 새로운 범용 아키텍처가 어떻게 빠르게 학습되고 빠르게 추론되며, 강력한 Transformer와 비슷하거나 일부 응용에서는 우수한 성능을 내는지 살펴볼 것입니다.
앞으로, Vision Mamba, VideoMamba, MambaMixer, Mamba-2와 같은 최근 연구 논문들을 자세히 살펴보며 Mamba가 이미지, 동영상, 시간 신호와 같은 다양한 데이터 모달리티로 확장되는 방법과 지속적인 개선이 어떻게 이루어지는지 살펴볼 것입니다.
2. 왜 새로운 모델이 필요한가요?
새 모델 아키텍처가 필요한 이유를 이해하기 위해, 최근까지 우리가 가지고 있던 두 가지 가장 유명한 시퀀스 모델을 간단히 살펴보겠습니다: Transformer와 Recurrent Neuronal Network (RNN):
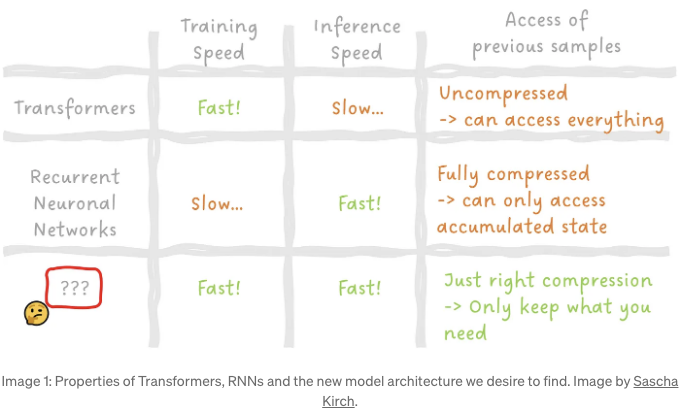
최종적으로, 우리의 목표는 빠르게 학습하고 빠르게 추론하는 모델을 가지면서도 작은 메모리 풋프린트를 가지며 시퀀스의 다른 샘플들의 모든 관련 데이터에 액세스할 수 있는 모델을 갖는 것입니다 (그 이상 그 이하로는 아니죠).
RNN과 Transformer를 매우 상위 수준에서 비교해 보겠습니다:
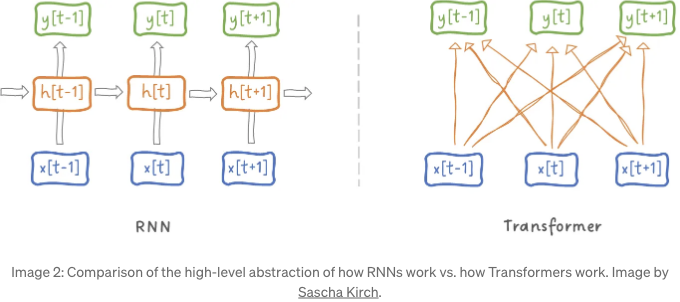
2.1 RNN 자세히 살펴보기
RNN에서 입력 x는 숨겨진 상태 h를 통해 출력 y를 얻습니다. 출력 y[t]는 오직 현재의 숨겨진 상태 h[t]와 현재 입력 x[t]에만 의존한다는 점을 주목하세요. 또한 현재 숨겨진 상태 h[t]는 이전 숨겨진 상태 h[t-1]과 현재 입력 x[t]에 의존합니다. 이에 따라 다음과 같은 영향을 미칩니다:
- 과거 입력 샘플은 과거 데이터 포인트의 정보를 압축한 숨겨진 상태를 통해서만 액세스할 수 있으며, 각 새로운 샘플마다 새 입력을 사용하여 업데이트해야 합니다.
- 우리는 과거 샘플에만 액세스할 수 있습니다.
- 입력의 길이에 관계없이 각 출력 당 계산 횟수는 일정하며, 계산의 총 횟수는 입력 시퀀스의 길이에 선형적으로 증가합니다.
RNN은 3의 이유로 추론 속도가 빠르지만, 1과 2의 이유로 훈련 중에 병렬화할 수 없습니다. 특히 상태의 고압축은 Transformer에 비해 RNN의 성능을 제약할 수 있습니다. 압축으로 인해 값싼 정보가 손실될 수 있으며, 특히 긴 시퀀스를 고려할 때 상태를 경사 기반 알고리즘으로 훈련해야 하기 때문에 사라지는 그래디언트와 같은 어려움이 발생할 수 있습니다.
2.2 Transformer는 어떤가요?
Transformer에서는 입력 시퀀스의 각 샘플이 직접 자신에게 그리고 시퀀스의 다른 모든 샘플에 어태션을 줍니다. N개의 샘플 시퀀스에서 각 개별 샘플은 다른 샘플에 얼마나 많이 어태션하는지 점수를 계산하며, 이것이 O(N²) 복잡성의 이유입니다. 이는 (바닐라 어텐션 메커니즘의 경우에) 해당합니다.
- 각각의 샘플 간에 전혀 압축이 없으며 상태는 NxN 크기입니다.
- 각 샘플은 이전 및 향후 샘플에 동시에 참석할 수 있습니다.
- 만약 우리가 자기 회귀 샘플링을 한다면 (예: 다음 단어 예측), 새로운 샘플을 고려하기 위해 모든 주의 맵을 다시 계산해야 합니다.
특히 2는 트랜스포머가 훈련 중에 잘 병렬화되고 예측 성능이 우수한 이유이며 1은 예측 성능이 우수한 이유입니다. 우리는 모든 것이 다른 모든 것에 참석하도록 두는 이 야만적인 방식을 통해 거의 모든 문제를 해결할 수 있습니다. 압축이 없기 때문에 관련 없는 것을 계산하는 자원을 낭비한다는 것을 상상하는 것이 어렵지 않습니다.
❓ 그 질문은 어떻게 하면 두 마리 토끼를 모두 잡을 수 있을까요? 빠른 훈련, 빠른 샘플링 및 메모리 측면에서의 효율성.
🤔 '맘바'가 정확히 이를 달성할 수 있는 후보인가요?
3. 구조화된 상태 공간 모델
먼저 기본 사항부터 시작해 봅시다. Mamba는 딥러닝을 위해 상태 공간 모델을 사용하는 아이디어 위에 구축됩니다. 시스템 이론에서 잘 알려진 상태 공간 모델은 입력 신호가 상태를 가진 시스템을 통과하여 발생하는 출력 신호 간의 관계를 설명합니다.

컴퓨터에서는 이산 데이터를 다루기 때문에 상태 공간 모델을 이산화해야 합니다. 이산 상태 공간 모델을 갖게 되면 순환 표현과 합성 표현 두 가지 다른 표현을 발견할 수 있습니다. 이 두 가지 표현은 동일하며 표준 SSM은 선형 및 시간 불변(LTI) 시스템이기 때문에 같습니다.
우리는 이 이중성을 활용하여 추론을 위해 순환 표현을 사용하고 훈련을 위해 합성 표현을 사용할 수 있습니다. 이는 입력 시퀀스의 길이에 선형적으로 변화하는 추론 시간과 모던 하드웨어 가속기에서 효율적으로 모델을 훈련할 수 있다는 것을 의미합니다.
4. 맘바가 나타났다
S4 (구조화된 상태 공간 시퀀스 모델)을 사용하면 입력 시퀀스의 길이에 선형적으로 변화하는 추론 시간을 가지는 학습 가능한 상태 공간 모델을 갖게 되며, 이 모델은 합성 표현을 활용하여 효율적으로 훈련할 수 있습니다. 뿐만 아니라, 이 모델은 막강한 트랜스포머에 비해 우수한 성능을 보여주었습니다 (최소한 제시된 실험에서).
S4가 표현을 전환하는 데 활용한 선형 시스템이라는 사실은 동시에 가장 큰 약점이기도 합니다. 각 입력 샘플은 행렬이 시간에 영향을 받지 않기 때문에 동일하게 처리됩니다. 이는 중요한 입력을 다르게 처리하거나 관련 없는 입력을 무시하는 것과 같이 중요한 작업을 수행할 때 큰 제약으로 작용합니다.
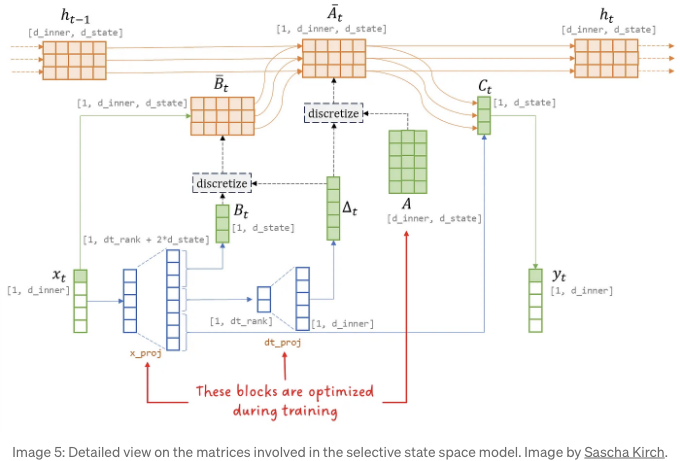
Mamba는 정확히 그것을 합니다: 우리가 원하는 선택성을 도입하기 위해 관련 행렬을 시간 변화형으로 만듭니다. 그 결과로 우리는 이제 시간 변화형 시스템을 가지게 되었고, 이로 인해 컨볼루션 표현을 더 이상 사용할 수 없게 되며, 따라서 빠르고 효율적인 훈련을 할 수 있는 가능성을 잃게 됩니다.
Mamba는 해당 문제를 해결하기 위해 병렬 스캔을 소개하고, 커널 퓨전, 병렬 연관 스캔 및 그래디언트 재연산을 결합한 기술을 사용하여 모델의 훈련을 가속화합니다.
또한 트랜스포머 블록과 마찬가지로 서로 쌓아서 깊은 네트워크를 구축할 수 있는 일반 아키텍처인 Mamba 블록을 제시합니다.
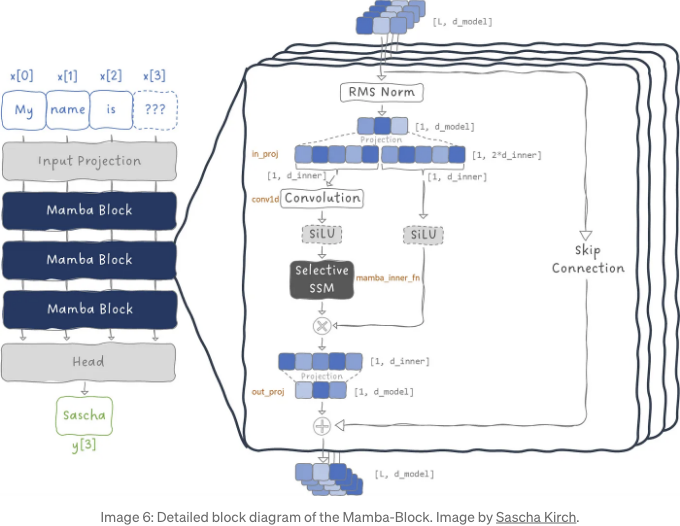
5. Vision Mamba — Mamba Applied on Images
Having a new general architecture for sequence modeling, the Mamba Block, history starts to repeat itself. Just like the Transformer was applied to images by the introduction of the Vision Transformer (ViT), Mamba is applied to images resulting in Vision Mamba (Vim).
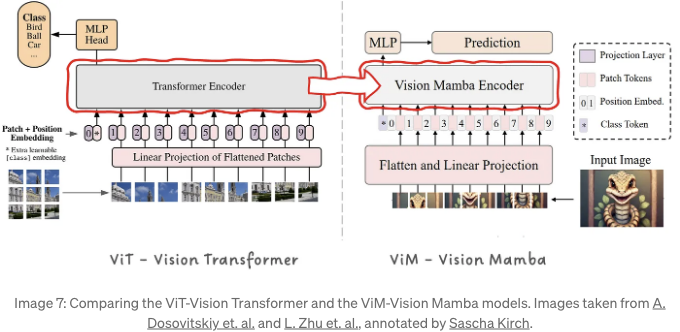
Vision Mamba는 Mamba 상태 공간 모델을 사용하여 새로운 일반적인 비전 백본을 정의하는 데 목표를 두고 있습니다.
이미지를 시퀀스로 표현하기 위해, 결국 Mamba는 여전히 시퀀스 대 시퀀스 모델이기 때문에 이미지를 패치로 나누고 풀어 헤친 다음 선형으로 투영하여 위치 인코딩과 결합한 후 Mamba 인코더 블록 스택으로 전달합니다. Mamba의 선형 스케일링 법칙은 고해상도 이미지에 특히 흥미로운데, ViT에서 소개된 이미지를 패치로 나누는 것은 Transformer의 어텐션 블록의 O(N²) 복잡성의 직접적인 결과였습니다. Mamba의 O(N) 복잡성을 갖는다면, 더 작은 패치 또는 더 높은 해상도의 이미지를 일부 컴퓨팅 자원만을 사용하여 처리할 수 있습니다. 사실, 어텐션 메커니즘이 없는 Vision Mamba는 DeiT(Data efficient Vision Transformer)보다 2.8배 더 빨랐으며, 1024x1024 해상도의 이미지에서 최대 86.8%의 GPU 메모리를 절약했습니다.
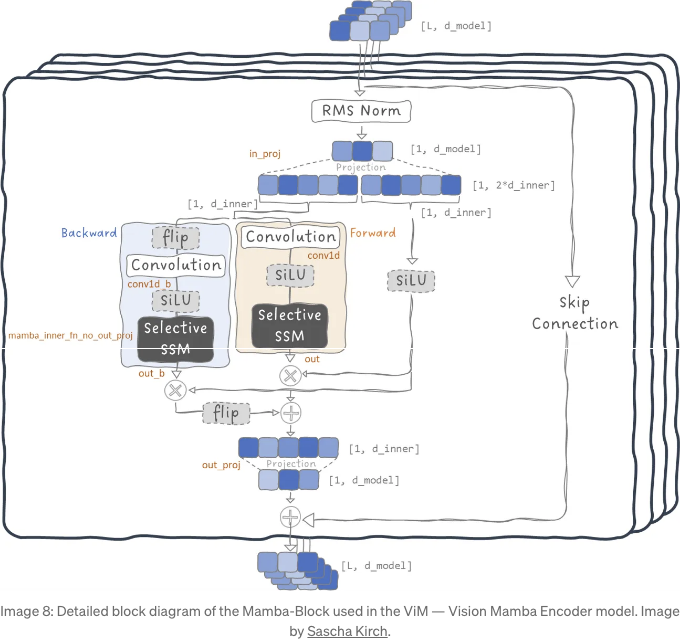
대부분의 시계열 신호와 달리, 각 샘플이 이전 샘플과 인과 관계를 갖는 시간 신호와 달리, 이미지는 이 속성을 갖지 않습니다. 이미지에서는 현재 픽셀 이전 및 이후의 다양한 픽셀 위치 사이에 장거리 종속성이 있습니다. 이 비인과적 표현을 처리하기 위해 Vision Mamba는 양방향 인코더 블록을 도입했는데, 이는 일반 시퀀스와 역으로 추론된 시퀀스를 포함하는 두 개의 SSMs를 포함합니다.
6. VideoMamba — 동영상 이해
Mamba는 딥 러닝의 최신 발전 상황을 매우 빠르게 따라잡아야 했습니다. 이전보다 더 많은 컴퓨팅 자원, 데이터 및 기존 모델을 활용하여, 딥 러닝은 이전에 다루기 너무 복잡하다고 생각되던 데이터 모달리티에 직면하고 있습니다. 따라서 Mamba가 동영상에 대처하는 데 얼마나 걸릴지는 시간 문제일 뿐이었습니다(그리고 이번에는 ViM이 arxiv에 게시된 후 2개월 이내였습니다).
VideoMamba는 Vision Mamba의 확장판이지만 동영상에 적용됩니다. 이미지가 아닌 동영상을 분류합니다.
비디오는 입력 데이터에 추가적인 시간적 차원을 제공합니다. 이전 방법들은 비디오를 처리하기 위해 3D 합성곱이나 트랜스포머를 사용했지만, 두 방법 모두 계산 및 메모리 사용 측면에서 매우 비용이 많이 듭니다. 비디오는 시간을 통해 장거리 의존성을 도입하는 반면, 프레임 간에는 픽셀이 종종 변경되지 않거나 약간만 변경되기 때문에 매우 중복적입니다(파란 하늘을 포함한 장면을 상상해보세요). 이러한 중복성을 다루는 한 가지 요령은 필요한 프레임 수를 줄이기 위해 주요 프레임을 추출하는 것이었습니다. 다시 말해, 선형 복잡성 O(N)을 가진 Mamba가 유용하게 사용됩니다.
VideoMamba의 아키텍처는 Vision Mamba와 매우 유사합니다. 입력을 패치로 분할하고 선형 투영을 수행한 후 Mamba 블록에 공급하기 전에 위치 인코딩을 추가합니다. 이제 위치 임베딩에 더 깊이 들어가 봅시다. 패치들의 공간 위치 임베딩 색인은 매 프레임마다 재설정되고 각 프레임에는 프레임 내 모든 패치에 대해 일정한 추가 시간 위치 임베딩이 제공됩니다.
Vision Mamba의 경우, 픽셀 간의 인과 관계를 다루기 위해 양방향 블록이 소개되었습니다. 여기에 추가적인 시간 차원을 추가하면 더 복잡해집니다. 실험에서 공간 차원을 다루기 전에 먼저 시도해보는 것이 더 나은 성능을 보였습니다.
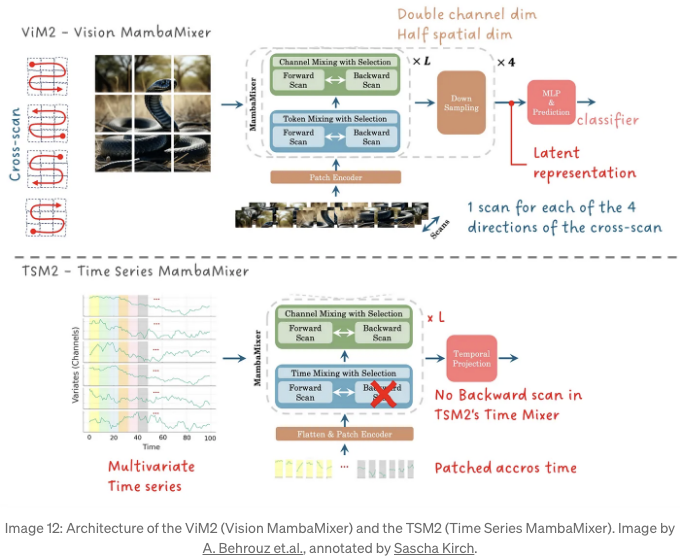
7. MambaMixer — 채널에 선택성 추가하기
이 기사에서 아직 언급하지 않은 작은 세부 사항 하나가 있습니다: Mamba 및 해당 변형은 각 채널에 SSM을 개별적으로 적용합니다. 이는 정보가 한 채널에서 다른 채널로 흐르지 않음을 의미합니다. 다르게 말하면 다음과 같습니다: 채널 간에 정보를 전송하는 선택이 없으며, 이는 Mamba가 다차원 데이터(예: 3가지 색상 채널을 갖는 이미지) 또는 다변량 시간 신호에서 관계를 찾는 능력을 제한합니다.
MambaMixer는 이 문제를 해결하는 깔끔한 작은 속임수로 처리합니다: 두 번째 SSM을 통과하기 전에 피쳐 맵을 전치합니다:
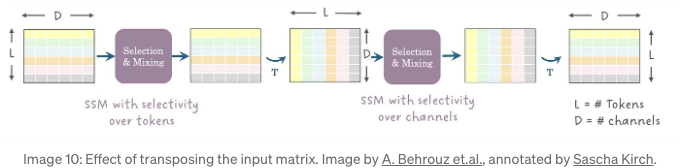
이러한 방식으로 SSM은 먼저 토큰 축을 대상으로 적용되고, 그런 다음 채널 축을 대상으로 적용됩니다. 개별 블록은 각각 TokenMixer 및 ChannelMixer라고 불립니다. TokenMixer와 ChannelMixer는 결합하여 MambaMixer 블록을 형성합니다.
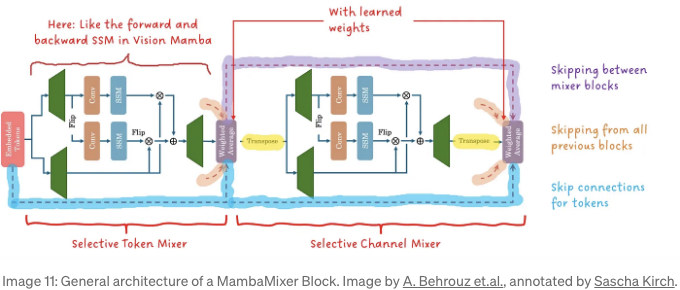
이론적으로 각 블록은 입력 패치 위의 다른 스캔 방향을 위해 여러 개의 SMM을 가질 수 있습니다. 여러 개의 MambaMixerBlock이 쌓여 MambaMixer를 구축합니다. 성능과 교육 안정성을 더 향상시키기 위해 이전 TokenMixer 및 ChannelMixer 블록의 출력은 학습된 가중 평균을 통해 결합됩니다.
논문에서는 MambaMixer 블록을 사용하여 두 가지 모델을 구축합니다: Vision MambaMixer (ViM2) 및 Time Series MambaMixer (TSM2). 이름에서 알 수 있듯이 ViM2는 이미지에 적용되고 TSM2는 다변량 시계열에 적용됩니다.
이 논문은 Vision Transformer (ViT)의 아키텍처를 간소화하기 위한 MLP Mixer 논문에서 강력한 영감을 받았습니다. 여기에서는 MLP Mixer를 간단히 소개한 내 게시물의 링크를 공유하겠습니다:
8. Mamba-2 — Attention과 SSMs 간의 간극을 좁히다
지금까지 Mamba는 다양한 응용 프로그램과 데이터 모달리티에 매우 성공적으로 적용되어 왔습니다. Transformer 아키텍처를 제쳐놓고 Transformer를 어떤 과제와 벤치마크에서 능가하는 Transformer의 강력한 경쟁자입니다. 그럼에도 불구하고 SSMs는 몇 가지 단점을 지니고 있습니다: 그들은 Transfomer와 그의 attention 메커니즘을 특별히 맞춘 딥 러닝 인프라와 맞서 있습니다. 더불어, Mamba의 선택적 병렬 스캔은 현대 GPU의 행렬 곱셈 유닛을 활용하지 못합니다.
Mamba-2는 SSM을 재정의하여 주목받는 이 최적화된 생태계와 현대 하드웨어 가속기의 빠른 행렬 곱셈 유닛을 활용할 수 있도록 하여, attention 메커니즘과의 이중성을 보여주고자 합니다.
특별히, SSM이 TxT 반분리 행렬의 용어로 정의되면 정확히 그것을 달성할 수 있습니다.
출력 Y의 계산은 입력 X와 SSM의 행렬 곱셈으로 정의됩니다. SSM은 행렬 A, B, C로 정의되며 반분리 행렬을 형성합니다. 이러한 행렬을 보유하면 블록 분해를 허용하여 행렬을 QxQ 차원의 하위 행렬로 나눌 수 있습니다.
대각선상의 결과 블록은 삼각 행렬입니다. 이러한 블록은 모두 동일한 항목을 공유하지 않으므로 병렬로 계산할 수 있습니다. 대각선 밖의 블록은 저랭크 분해를 통해 더 단순화할 수 있습니다. 동일한 요인이 여러 블록에 나타나기 때문에 한 번 계산하고 나중에 재사용할 수 있어 속도를 높일 수 있습니다.
이 상태 공간 이중성(SSD)을 정의함으로써 저자들은
- SSM과 주의를 연결하는 방법을 보여줍니다,
- 세미분할 행렬 변환을 사용하여 SSM을 재정의하면 메모리를 적게 사용하고 GPU의 전용 행렬 곱셈 코어를 활용하는 빠른 알고리즘의 구현이 가능해집니다,
- 새로운 Mamba-2 블록의 설계는 텐서 병렬처리나 시퀀스 병렬처리와 같은 현대 병렬화 기술을 적용할 수 있도록 합니다,
- 트랜스포머의 주목받는 다중 헤드 패턴의 아날로그 개념을 SSM에 도입하며 다중 헤드 SSM(MHS)와 같은 패턴을 보여줍니다.
결론적으로, SSD 프레임워크는 주의와 SSM처럼 훨씬 작은 메모리 풋프린트를 가지며 SSM보다 2배에서 8배 빠른 이유는 핵심적인 부분에 행렬 곱셈을 사용하기 때문입니다.
9. 결론
Mamba 상태 공간 모델은 트랜스포머와 RNN에 대안이 되는 유망한 아키텍처로, 어떤 데이터 모달리티에도 적용할 수 있는 새로운 세대의 범용 아키텍처를 구축하는 데 기여할 수 있습니다.
잠시 만에, 맘바와 같은 모델들이 딥러닝에서 많은 문제에 성공적으로 적용되었습니다.
시스템 이론과의 밀접한 관련, 고급 대수학의 적용, 그리고 현대 딥러닝 생태계가 트랜스포머에 맞춰져 있어서, 이 새로운 모델 패밀리를 수용하는 것이 연구자들에게는 어려울 수도 있습니다. 하지만 어떤 연구자들의 노고와 헌신 덕분에, 맘바와 같은 모델들은 점점 더 빨라지고 효율적으로 현대 하드웨어 가속기에서 작동하며, 표준 딥러닝 레이어에 통합되어 개인 프로젝트에 쉽게 통합될 수 있도록 점점 더 쉬워지고 있습니다.
계속해서 읽기: Part 2:
시각적으로 설명된 구조화된 State Space 모델들
추가 참고 자료 및 자원
블로그 글
- Mamba 및 State Space 모델에 대한 시각적 안내
- 주석이 달린 S4
- 최적 다항식 투영을 사용한 재귀 메모리
- CUDA로 병렬 접두사 합(Scan)
논문:
- S4: Efficiently Modeling Long Sequences with Structured State Spaces by A. Gu 등., 2021년 10월 31일
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces by A. Gu 등., 2023년 12월 1일
- Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model by L. Zhu 등., 2024년 1월 17일
- VideoMamba: State Space Model for Efficient Video Understanding by K. Li 등., 2024년 3월 11일
- MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection by A. Behrouz 등., 2024년 3월 29일
- Mamba-2: Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality by A. Gu 등., 2024년 5월 31일
- S5: Simplified State Space Layers for Sequence Modeling by J. Smith 등., 2022년 8월 9일
- HiPPO: Recurrent Memory with Optimal Polynomial Projections by A. Gu 등., 2020년 8월 17일
- LSSL: Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers by A. Gu 등., 2021년 10월 26일
- DSS: Diagonal State Spaces are as Effective as Structured State Spaces by A. Gupta 등., 2022년 3월 27일
- S4D: On the Parameterization and Initialization of Diagonal State Space Models by A. Gu 등., 2022년 6월 23일
- Mamba 모델의 숨겨진 주의력 by A. Ali 등., 2024년 3월 3일