
샌디에고에 본부를 둔 뉴 스쿨 오브 아키텍처 & 디자인에 따르면, 제품 디자인은 기업이 고객에게 판매할 새 제품을 만드는 것입니다. 제품 디자인은 넓은 개념이며, 본질적으로는 새로운 제품을 이끌어내기 위한 효과적이고 효율적인 아이디어 생성 및 개발을 통한 디자인 프로세스입니다. 휴스턴에 본부를 둔 제품 개발 회사인 Imaginationeering은 제품 디자인 개념화를 새 제품 개발 초기 단계나 기존 제품의 업그레이드 중 중요한 단계로 정의합니다. 제품 디자인 개념화는 제품이 어떻게 작동할지 또는 최종 모습이 어떻게 될지에 대한 명확한 아이디어나 방향이 없을 때 필요합니다.
본 게시물에서는 Generative Artificial Intelligence(생성적 인공 지능)를 활용하여 제품 디자인 개념화를위한 Stability AI의 최신 Stable Diffusion XL 1.0 (SDXL 1.0) 모델의 텍스트-to-이미지 및 이미지-to-이미지 생성 및 세밀 조정 기능을 살펴볼 것입니다. 우리는 새 전기 모터 스쿠터 디자인을 위한 여러 개념을 개발할 것이며, 기존의 세련되고 스포티한 유럽 자동차 스타일에서 영감을 받을 것입니다. Google Research의 DreamBooth와 Hugging Face의 AutoTrain을 함께 사용하여 해당 자동차 스타일을 사용하여 SDXL을 세밀하게 조정하는 방법을 배울 것입니다. 그런 다음 세밀하게 조정된 SDXL 모델과 프롬프트 엔지니어링 기술을 사용하여 거친 스케치, 컬러 마커 렌더링 및 사실적 제품 이미지의 여러 변형을 빠르게 생성하는 방법을 알아볼 것입니다. 모든 세밀 조정 및 이미지 생성은 Amazon Web Services(AWS)의 Amazon SageMaker Studio에서 진행됩니다.

Stable Diffusion XL (SDXL)
Clipdrop에 따르면, 스테이블 디퓨전 XL 1.0은 Stability AI가 출시한 스테이블 디퓨전 텍스트-이미지 모델 스위트에서 가장 진보된 개발입니다. Hugging Face에 따르면, 스테이블 디퓔전은 CompVis, Stability AI 및 LAION 연구원 및 엔지니어들에 의해 만들어진 텍스트-이미지 잠재 디퓨전 모델(LDM)입니다. 잠재 디퓨전은 낮은 차원의 잠재 공간에서 확산 과정을 적용하여 메모리 및 계산 복잡성을 줄이는 방법입니다. 이 특정 유형의 디퓨전 모델은 논문에서 제안되었습니다. 고해상도 이미지 합성을 위한 잠재 디퓨전 모델. 이미지 형성 과정을 잡음 제거 오토인코더의 순차적 적용으로 분해함으로써, 디퓨전 모델은 이미지 데이터 및 그 이상의 합성 결과에서 최첨단 결과를 달성합니다.
DreamBooth
Hugging Face에 따르면, Google Research에서 개발한 DreamBooth는 주제로 하는 이미지 몇 장만 남기면 스테이블 디퓨전과 같은 텍스트-이미지 모델을 개인화하는 방법입니다. 이를 통해 모델은 다양한 장면, 자세 및 시각에서 주제의 이미지를 생성할 수 있습니다. 논문인 Subject-Driven Generation을 위한 DreamBooth: Fine Tuning Text-to-Image Diffusion Models에서 자세한 정보를 찾을 수 있습니다. 이 글에서는 독특한 스포츠 카 디자인 스타일의 이미지를 생성하기 위해 DreamBooth를 사용하여 SDXL을 세밀 조정할 것입니다.
Hugging Face AutoTrain Advanced
Hugging Face 🤗는 AI를 제품 및 업무에 쉽게 통합할 수 있도록 오픈 소스 자원을 구축합니다. Hugging Face의 미션은 좋은 기계 학습을 대중화하는 것입니다. Hugging Face의 AutoTrain은 자연 언어 처리 (NLP) 작업, 컴퓨터 비전 (CV), 음성 및 심지어 테이블 작업을 위해 최첨단 모델을 훈련하는 노코드 도구입니다. AutoTrain은 사용하기 쉽게 설계되었으며, 목표는 데이터 과학자나 기계 학습 엔지니어뿐만 아니라 비전문가도 어떤 작업을 위한 최첨단 모델을 훈련하기 쉽게 만드는 것입니다.
AutoTrain Advanced를 사용하면 고급 사용자들이 작업 당 사용되는 하이퍼파라미터를 제어할 수 있습니다. 이를 통해 다른 하이퍼파라미터로 여러 모델을 훈련하고 결과를 비교할 수 있습니다. 이 게시물의 많은 코드는 Hugging Face의 AutoTrain DreamBooth 노트북 예제를 기반으로 합니다.
Amazon SageMaker Studio
AWS는 Amazon SageMaker Studio를 머신 러닝(ML)을 위한 웹 기반 통합 개발 환경(IDE)으로 설명합니다. 이를 통해 머신 러닝 모델을 구축, 훈련, 디버깅, 배포 및 모니터링할 수 있습니다. SageMaker Studio는 데이터 준비부터 실험 및 제품 생산까지 모델을 개발하는 데 필요한 모든 도구를 제공하며 생산성을 향상시킵니다. 이 게시물에서는 Studio의 Jupyter 노트북에서 ML 코드를 개발하고 실행하는 기능을 사용할 것입니다.
소스 코드
이 게시물의 오픈 소스 코드는 모두 GitHub에서 확인할 수 있으며 LoRA 가중치도 포함되어 있습니다. README 파일에는 생성된 이미지 샘플 및 프롬프트 예제도 포함되어 있습니다.
SDXL Base 및 Refiner 모델 사용하기
먼저, 우리는 세밀한 조정 없이 무엇을 생산할 수 있는지 SDXL 1.0 베이스 모델 (stabilityai/stable-diffusion-xl-base-1.0)을 살펴볼 것입니다. 또한 SDXL 1.0 리파이너 모델 (stabilityai/stable-diffusion-xl-refiner-1.0)도 사용할 거에요. 허깅 페이스에 따르면, SDXL은 잠재적 확산을 위한 "전문가 앙상블" 파이프라인으로 구성되어 있어요. 베이스 모델은 (잡음이 있는) 잠재요소를 생성하고, 이후 최종 제거 단계에 특화된 개선 모델로 추가로 처리됩니다. 베이스 모델은 리파이너 없이도 독립적인 모듈로 사용할 수 있어요.
PyTorch 기반 파이프라인은 CPU 또는 GPU 기반 인스턴스에서 실행할 수 있어요. 그러나 제 테스트에 따르면, GPU는 CPU보다 이미지를 평균 20배 빠르게 생성할 수 있어요. 저는 아마존 세이지메이커 스튜디오에서 Python 3.10 GPU 최적화 이미지 및 Python 3 커널을 사용하고 있으며, 노트북 환경에는 ml.g5.4xlarge 인스턴스 유형을 사용하고 있어요. 아마존 EC2 G5 인스턴스에는 단일 NVIDIA A10G Tensor Core GPU가 포함되어 있어요.
기본적으로 AWS 계정에는 ml.g5.4xlarge와 같은 대규모 GPU 기반 아마존 세이지메이커 스튜디오 인스턴스에 액세스할 수 없어요. 이러한 인스턴스에 액세스하려면 AWS 서비스 할당량 콘솔을 사용하세요. 콘솔을 찾는 데 도움이 필요하면, 새로운 아마존 Q에게 간단히 물어보세요.
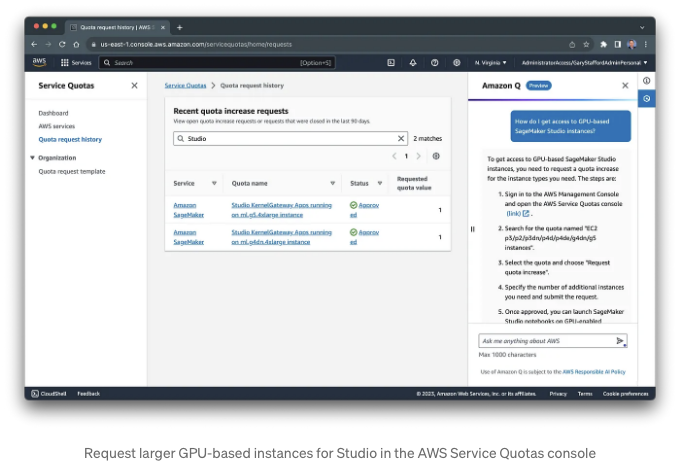
먼저, Hugging Face의 autotrain-advanced Python 패키지를 pip을 이용해 설치해야 합니다.
다음 명령을 사용하여 PyTorch의 버전 및 NVIDIA GPU의 정보를 확인할 수 있습니다:
이제, SDXL 1.0 베이스와 리파인 모델로 구성된 확산 파이프라인을 사용하여 여러 이미지를 생성할 것입니다. 이 모델들을 사용하는 것이 처음이라면 Hugging Face로부터 다운로드할 것입니다. 연결에 따라 다소 시간이 걸릴 수 있습니다. 베이스 모델 파일은 약 14 GB, 리파이너는 약 12 GB입니다. Amazon SageMaker Studio에서 Hugging Face 모델은 /home/sagemaker-user/.cache/huggingface/hub 디렉토리에 있습니다.
먼저 아래 코드에서 보이는 것처럼, 우리는 베이스 모델 추론 단계(80)와 리파이너 모델 추론 단계(20)의 4:1 비율을 사용하고 있음을 유의해 주세요. 다음 섹션에서 이 관계를 더 자세히 살펴볼 것입니다. 두 번째로, 파이프라인의 첫 번째 단계에서 SDXL 베이스 모델을 사용하여 잠재 이미지를 생성하고 있음을 주목해 주세요. 논문 "잠재 확산 모델을 활용한 고해상도 이미지 합성"에 따르면, LDMs로 이미지는 고주파, 지각하기 힘든 세부사항이 추상화된 효율적이고 저차원의 잠재 공간에 저장됩니다. 마지막으로, 베이스 모델과 리파이너 모델에 각각 다르게 적용된 양-음의 두 가지 다른 세트에 유의해 주세요.
아래는 조정되지 않은 SDXL 베이스 모델을 사용하여 생성된 몇 가지 현실적인 스쿠터 이미지들입니다. 베이스 모델과 위의 프롬프트를 사용하여 얻어진 전기 스쿠터는 거의 균일하게 전기식 킥보드 형태의 모터라이즈드 E-스쿠터와 전통적인 모터 스쿠터 사이로 나누어집니다. 생성된 이미지에서, 당신은 베이스 모델의 파라메트릭 메모리에 Vespa, Segway, Suzuki, Honda, Kawasaki, Yamaha 등과 같은 일반적인 스쿠터 브랜드의 영향을 관찰할 수 있습니다.

推론 단계
인터넷에는 리파이너 모델의 유용성, 사용할 추론 단계수, 그리고 베이스와 리파이너 모델 추론 단계 비율에 대한 다양한 의견이 많이 있어요. 제가 Olivio Sarikas의 안정적인 디퓨전 팁을 모두 보기 위해 YouTube를 팔로우하고 있어요. Olivio는 SDXL - 최고의 빌드 + 업스케일러 + 단계 안내 비디오에서 베이스와 리파이너 모델 추론 단계의 80/20 비율을 추천하고 계셔요.
아래에서 여섯 가지 변형을 통한 이미지 생성 테스트 결과를 확인할 수 있어요. 모든 이미지는 리파이너 모델 없이 베이스 모델만 사용하여 생성되었어요. 다양한 추론 단계가 적용되었어요. 왼쪽에서 오른쪽으로, 위에서 아래로, 추론 단계는 5, 10, 25, 50, 100 및 150이에요. 결과를 분석해보니, 100 이상부터는 개선이 미미하며, 200 단계까지 가도 (표시되지 않음) 큰 변화가 없었어요. 이 게시물의 대부분 이미지는 베이스 모델의 추론 단계에 80-120 단계를 사용한 뒤 리파이너 모델을 적용했어요.
아래에서 두 개의 이미지 생성 테스트를 확인할 수 있어요. 모든 이미지는 베이스 모델을 100 단계로 사용하고 리파이너 모델을 다양한 추론 단계로 사용하여 생성되었어요. 왼쪽에서 오른쪽으로, 위에서 아래로, 추론 단계는 0, 5, 10, 25, 50 및 100이에요. 결과를 분석해보니, 저는 Olivio의 의견에 동의해요. 4:1 또는 심지어 5-6:1 비율이 최적이라고 생각해요. 제 경험상, 너무 많은 리파이너 단계는 이상한 이미지 이상점이나 특정 영역의 디테일 손실을 초래할 수 있어요. 이 게시물의 대부분 이미지는 베이스 모델의 추론 단계에 80-120 단계를 사용하고 리파이너 모델에 15-25 단계를 사용했어요.

DreamBooth를 사용하여 SDXL 베이스 모델 파인튜닝하기
위에 표시된 SDXL 베이스 모델의 결과는 인상적이었지만, 제품 디자이너들은 종종 많은 다양한 소스에서 영감을 찾습니다. 이 게시물에서는 인터넷에서 찾은 최신형 Mercedes-AMG GT 쿠페의 이미지를 사용해 전기 스쿠터 디자인에 영향을 미치겠습니다. Mercedes는 자신들의 Mercedes-AMG GT 스타일을 설명할 때 고성능, 기술 리더십, 최상의 매력, 폭발적인 힘, 절대적인 호화로움과 같은 구문을 사용합니다.
아래는 베이스 모델을 파인튜닝하는 데 사용된 대략 20개의 이미지 중 일부입니다. 파인튜닝을 위해 이미지를 1024 x 1024 픽셀 정사각형으로 스케일링하고 잘라내는 것이 좋습니다. 그러나 768 x 768 및 512 x 512도 지원됩니다. 이미지를 스케일링하고 자르는 것이 파인튜닝에 필요한지에 대한 의견은 분분합니다. 저는 모델을 파인튜닝하기 위해 사용된 이미지를 가장 긴 길이가 1024 픽셀이 되도록 스케일링하여 매우 좋은 결과를 얻었습니다.

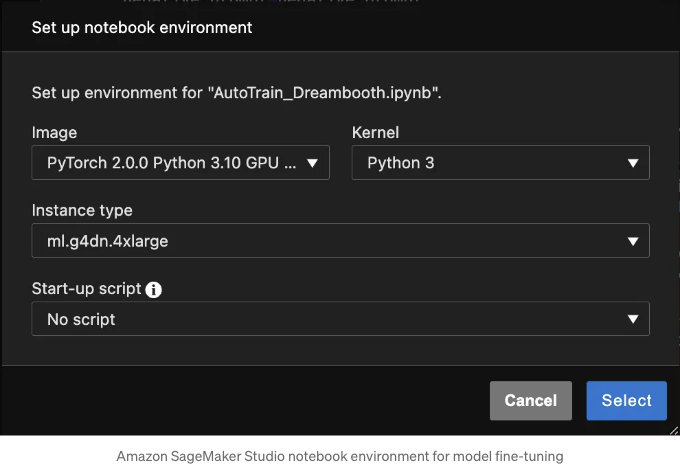
Amazon SageMaker Studio에서는 Python 3.10 GPU 최적화 이미지와 Python 3 커널을 사용하여 PyTorch 2.0.0을 사용하고 있습니다. 노트북 환경에는 ml.g4dn.4xlarge 인스턴스 유형을 사용하고 있습니다. Amazon EC2 G4 인스턴스에는 단일 NVIDIA T4 GPU가 포함되어 있습니다.
Rare Tokens
미세 조정 작업을 위한 도전 과제는 확산 모델이 이미 '어휘'를 보유하고 있다는 것입니다. 미세 조정 시, 우리는 새로운 주제를 기존 어휘에 심어주려고 합니다. 그렇다면 새로운 주제를 어떻게 참조할까요? 희귀 토큰은 일반적인 기법 중 하나입니다. 논문 "DreamBooth: 주제 기반 생성을 위한 텍스트-이미지 확산 모델 미세 조정"의 저자들은 희귀 토큰 식별자로 주어진 주제(예: 고유한 스포츠카 디자인 스타일)를 나타내는 기술을 제안합니다. 우리는 입력 이미지와 텍스트 프롬프트로 텍스트-이미지 모델을 미세 조정하며, 이는 고유 식별자 뒤에 주제의 클래스 이름이 오는 고유 식별자가 포함된 텍스트 프롬프트를 사용합니다(예: "a sks dog"에서 "sks"가 희귀 토큰이고 "dog"가 클래스입니다). 목표는 모델의 파라미터 메모리에서 다른 주제와 강하게 연관되지 않은 희귀(드문) 토큰을 사용하는 것입니다. sks, oue, hta, hmv와 같은 희귀 토큰의 예로 "sks"가 있습니다. 희귀 토큰은 다음과 같이 인스턴스 프롬프트의 일부입니다.
다음으로, 미세 조정을 시작하기 위해 autotrain dreambooth 명령을 사용할 것입니다. 모든 사용 가능한 명령과 인수를 살펴보려면 노트북에서 !autotrain dreambooth --help 명령을 사용할 수 있습니다. 모델을 미세 조정하는 데 걸리는 시간은 훈련 이미지의 수 및 훈련 중인 인스턴스의 유형에 따라 다를 것입니다. 제 테스트에서 미세 조정하는 데 약 110분이 소요되었습니다. LoRA(대규모 언어 모델의 낮은 순위 적응)를 사용한 미세 조정 과정입니다. Hugging Face의 Diffusers Adapters(텍스트 역전, LoRA, 하이퍼네트워크)는 전체 모델을 다시 훈련하거나 미세 조정하지 않고도 특정 스타일의 이미지를 생성하기 위해 확산 모델을 수정할 수 있습니다. 어댑터 가중치는 일반적으로 사전 훈련된 모델의 작은 일부분에 불과하며 이로 인해 이식성이 매우 뛰어납니다. Diffusers는 어댑터 가중치를 로드하는 사용하기 쉬운 LoaderMixin API를 제공합니다.
게시물의 미세 조정 과정은 어댑터 가중치 파일인 pytorch_lora_weights.safetensors로 이어집니다. 제 테스트에서 나온 어댑터 가중치 파일의 크기는 약 23.4 MB였습니다.
파인 튜닝된 SDXL 모델의 결과물을 확인할 수 있습니다. 동일한 프롬프트를 사용하여 일부 이미지를 생성했습니다:
다음은 파인 튜닝된 SDXL 1.0 베이스 모델에 의해 생성된 멋진 사진 같은 이미지들입니다. 이들 이미지는 명확하게 Mercedes-AMG GT 트레이닝 이미지의 영향을 보여줍니다. 이 이미지들이 생성된 것이라는 것을 믿기 어렵군요! 사용된 프롬프트에는 이제 Mercedes-AMG GT 스타일과 연관된 동일한 Stable Diffusion rare token (oue) 및 Fine-tuning 프롬프트에 사용된 Stable Diffusion 클래스 이름 (car)이 포함되어 있습니다, "... oue car의 사진 ...".

파인 튜닝된 SDXL 모델을 사용한 이미지 생성
핀튠 모델을 구현하는 데 사용된 코드의 주요 차이점은 diffusers.loaders.StableDiffusionXLLoraLoaderMixin 클래스에서 load_lora_weights 메서드를 사용하는 것입니다. 이 클래스는 SDXL에 특화된 LoRA 로딩/저장 코드를 포함하며 LoraLoaderMixin을 재정의합니다. Hugging Face 문서에 따르면 load_lora_weights 메서드는 pretrained_model_name_or_path_or_dict에 지정된 LoRA 가중치를 self.unet 및 self.text_encoder로 로드합니다.
초기 제품 스케치 생성
많은 제품 디자이너는 새로운 아이디어에 대한 초기 스케치로 시작합니다. 스케치에서 세부 사항과 색상을 피하는 것은 디자이너가 빠르게 반복하고 제품의 대략적인 디자인에 집중할 수 있게 합니다. SDXL 이미지를 사용하여 전기 모터 스쿠터의 흑백 스케치를 생성하는 프롬프트를 구성해 봅시다. subject_prompt에 oue rare 토큰에 대한 언급이 있습니다. 이 토큰은 메르세데스-AMG GT의 자동차 스타일링을 반영해야 하며 생성된 스쿠터 스케치에 적용될 것입니다.
아래는 핀튠 모델과 위의 프롬프트 변형을 사용하여 생성된 다양한 초기 제품 스케치 중 일부입니다. 생성된 스쿠터 디자인은 주로 전기 모터 스쿠터이며 킥스타일 전동 스쿠터보다 많습니다.

컬러 마커 렌더링 생성
더 나은 제품 디자인을 위해 물감으로 만든 렌더링을 생성할 수 있습니다. 제품 디자이너는 새로운 제품 아이디어에 대한 컬러 마커 렌더링을 자주 만듭니다. 우리는 검은색과 흰색의 초안에서 출발하여 긍정적 및 부정적 프롬프트를 수정함으로써 일렉트릭 스쿠터 아이디어에 대한 컬러 마커 렌더링으로 빠르게 전환할 수 있습니다.
아래에는 모델을 세밀하게 조정하고 위의 프롬프트 변형을 사용하여 생성된 많은 고도의 스타일화된 컬러 마커 렌더링 중 일부만 표시되어 있습니다. 이미지는 몇 가지 작은 프롬프트 변형을 사용하여 생성되었으며 원하는 룩 앤 필을 달성하도록 세밀하게 조정되었습니다.

Below are additional colored marker renderings in a wide format (768 x 1024 pixels) versus the typical square format (1024 x 1024 pixels) of SDXL-generated images.

Generating Photorealistic Images
포토리얼리스틱 제품 프로토타이핑은 과거에는 고급 사진 편집 도구와 컴퓨터 지원 설계(CAD) 소프트웨어의 등장에도 불구하고 복잡하고 시간이 많이 걸리는 작업이었습니다. 그러나 최근에 발전한 생성적 AI 및 잠재 확산 모델로 빠른 포토리얼리스틱 제품 프로토타이핑이 가능해졌습니다.
다시 한번 동일한 파이프라인 구조를 따라 시행함으로써 우리의 프롬프트를 수정하여 굵고 흑백 스케치에서 색칠된 마커 렌더링으로 이후에는 세밀하게 조정된 SDXL 베이스 모델로 포토리얼리스틱 이미지로 전환할 수 있습니다. 우리는 주간 도시 풍경에서 우리의 스쿠터 디자인의 포토리얼리스틱 이미지로 시작할 것입니다.
아래는 세밀하게 조정된 모델과 위에서 언급한 프롬프트를 사용하여 생성된 스쿠터 컨셉의 몇 가지 포토리얼리스틱 이미지입니다.

낮 시간 환경에서 생생한 도시의 야간 환경으로 손쉽게 이동할 수 있도록 우리의 프롬프트를 다시 조정해봅시다.
한 번 더 말하지만, 세밀하게 조정된 모델과 위의 프롬프트 변형으로 생성된 우리의 스쿠터 컨셉의 사실적인 이미지를 볼 수 있습니다. 야간 설정은 컨셉 스쿠터의 LED 조명을 강조합니다.

결론
이 포스트는 Stability AI의 최신 SDXL 1.0 베이스 및 리파이너 모델의 생성 AI를 활용하는 방법을 살펴보았어요. 특히 제품 디자인 개념화를 위한 텍스트에서 이미지로, 이미지에서 이미지로의 생성 및 세부 조정 기능에 중점을 두었답니다. 저희는 기존의 고급 스포츠카에서 영감을 받아 새로운 전기 모터 스쿠터 컨셉을 개발했어요. 또한, 구글 리서치의 DreamBooth와 Hugging Face의 AutoTrain을 사용하여 SDXL을 해당 고유한 스포츠카 스타일로 세부 조정하는 방법도 배웠답니다. 마지막으로, 세밀하게 조정된 SDXL 모델과 고급 프롬프팅 기술을 사용하여 제품 스케치, 마커 렌더링, 사실적인 제품 모의도를 빠르게 여러 가지 변형으로 만들어내었어요. 다음에는 아마도 우리가 세밀하게 조정된 모델을 사용하여 청소기, 게이밍 워크스테이션, 잔디깎이, 물병 또는 심지어 보트를 디자인할지도 몰라요!

아직 Medium 회원이 아니고 제철과 같은 작가를 지원하고 싶다면, 여기에서 가입하세요: https://garystafford.medium.com/membership
이 블로그는 제 의견을 대표하며, 제 고용주인 Amazon Web Services (AWS)의 의견은 아니에요. 모든 제품 이름, 로고 및 브랜드는 각 소유자의 재산입니다.
PlainEnglish.io 🚀
인 플레인 잉글리쉬 커뮤니티에 참여해 주셔서 감사합니다! 떠나시기 전에:
- 작가를 클랩하고 팔로우하세요️
- 인 플레인 잉글리쉬에 글을 쓸 수 있는 방법을 배우세요️
- 팔로우해 주세요: X | LinkedIn | YouTube | Discord | Newsletter
- 다른 플랫폼도 방문해 보세요: Stackademic | CoFeed | Venture